ENIGMA Carbon Census 1
CompletedResearch Question
For 83 groundwater- and necromass-derived carbon compounds proposed for community
enrichment and isolate phenotyping, what is known about (1) their environmental
distribution, (2) the catabolic pathways that could utilize them, (3) the organisms
encoding those pathways, and (4) how those pathways co-occur within and across
organisms — and which ENIGMA isolates or environmentally observed organisms are
likely utilizers of each compound?
Overview
The Carbon Census selected 83 compounds (59 from SSO groundwater, 24 from necromass)
spanning natural-product chemical classes (alkaloids, shikimates/phenylpropanoids,
terpenoids, fatty acids, polyketides). This project assembles a knowledge census
linking each compound to candidate degradation pathways, the organisms encoding them,
within/across-organism pathway co-occurrence, and predicted utilizers in the ENIGMA
isolate collection and environmental data — to guide enrichment design and
genetic-determinant discovery.
Key Findings
1. The census is mostly dark: 74 of 83 compounds have no isolate-level utilizer call
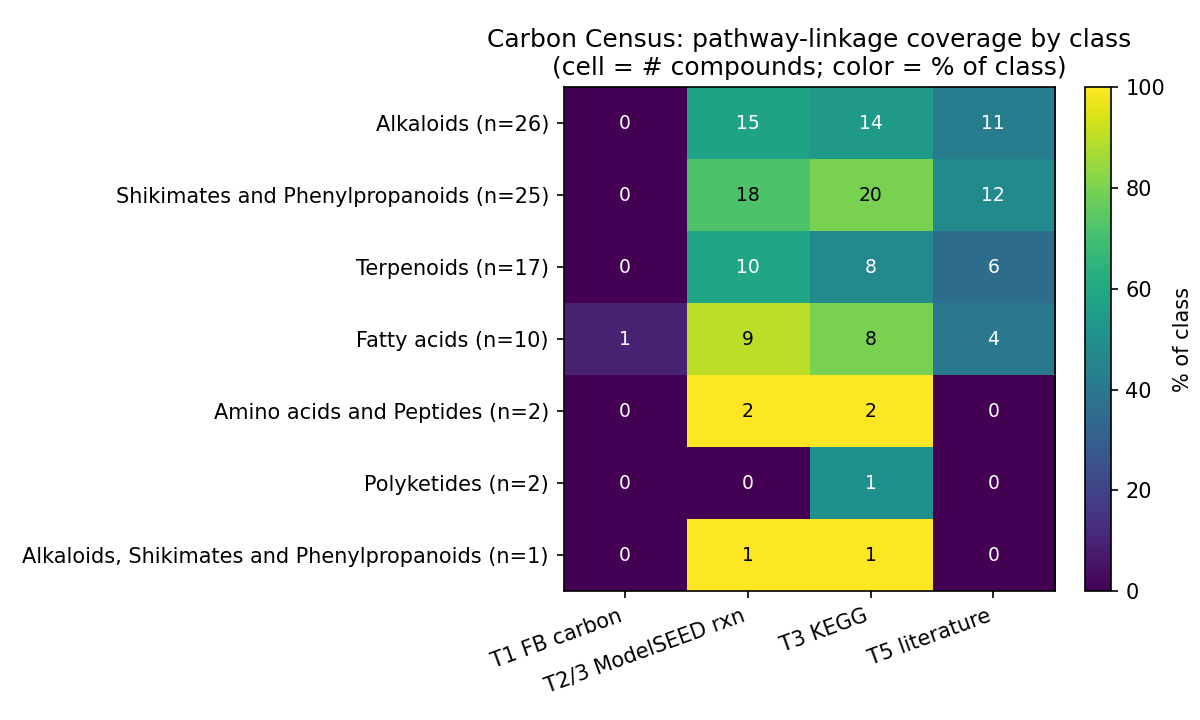
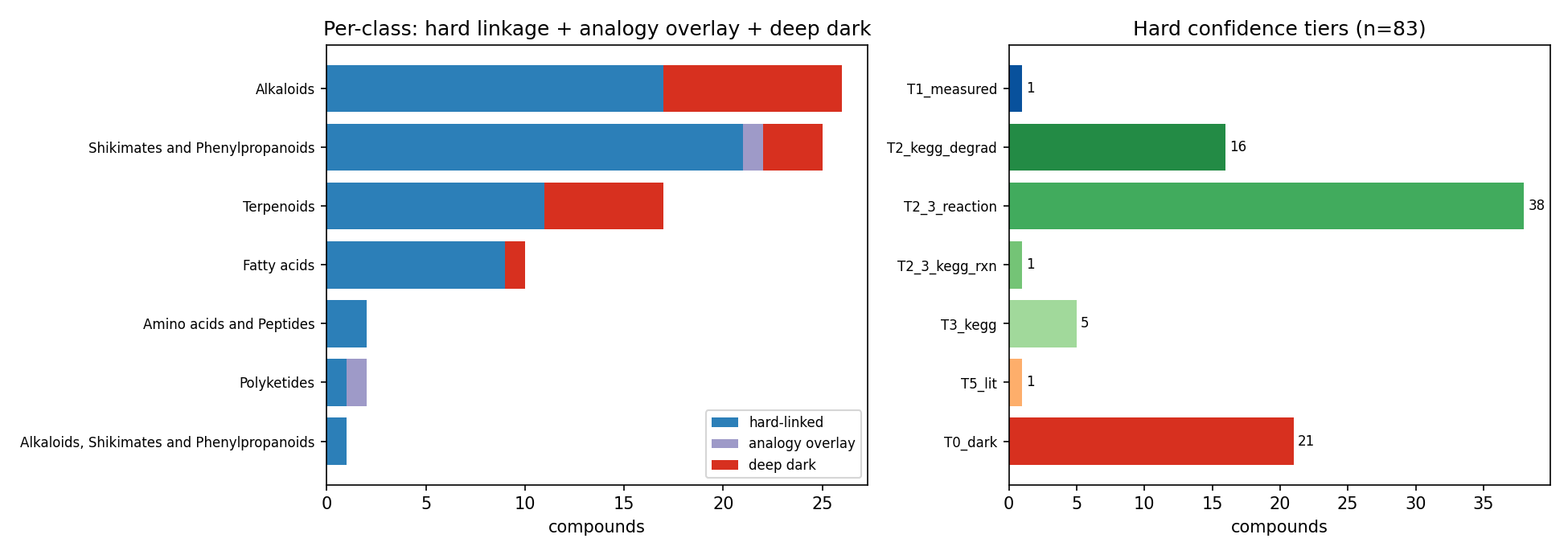
The governing result is a gap, not a coverage claim. Of 83 compounds (59 SSO-groundwater + 24 necromass), all 83 resolved to structures (InChIKey via PubChem), 54 linked to KEGG, but only 9 are "callable" (review I1: callable = an ENIGMA-isolate utilizer call or a Tier-1 measured RB-TnSeq carbon-source fitness experiment). Eight are callable on an enigma_isolate_call basis (≥1 ENIGMA-isolate prediction with a catabolic, compound-degrading reaction in a genome); a ninth — lauric acid — is callable on a measured_fitness basis: it has a Tier-1 measured carbon-source growth experiment in the Fitness Browser, confirmed structurally by an InChIKey re-match (NB02c). Lauric acid's Fitness Browser organism is a reference bacterium, not an ENIGMA isolate, so the ENIGMA-isolate deliverable (a) is unchanged. The remaining 74/83 (89%) are organism-dark: the genetic determinants of their utilization are not linkable via the queried BERDL and curated resources. This is resource-darkness, not proof of absence from science — class-level catabolic literature exists for several of these compounds (e.g. monoterpenes, nicotine), and the project's own literature-rescue channel (NB02b) returned zero only because it used a shallow PubMed-title screen, which is a method floor rather than evidence of absence (see Limitations). This dark list, stratified by reason and chemical class, is the actionable enrichment-design output — it separates not-linkable-here compounds (candidate discovery targets) from the small characterize-known set, and a literature/PaperBLAST pass would reclassify some of the dark set.
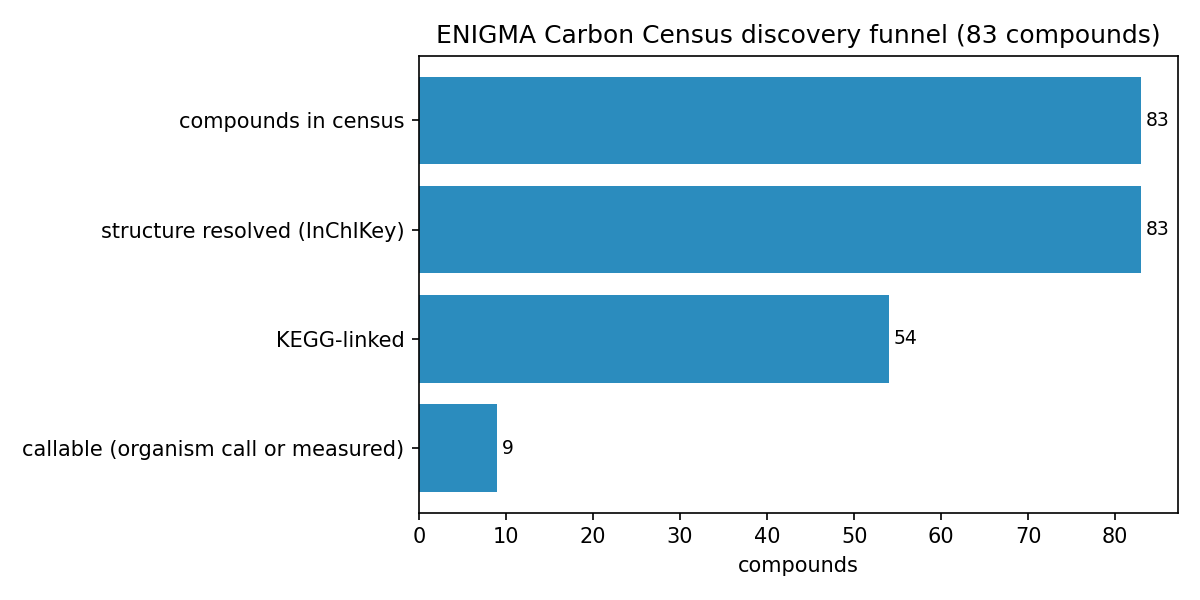
The funnel: 83 compounds → 83 structure-resolved → 54 KEGG-linked → 9 callable; 74 organism-dark.
Organism-dark breakdown by bucket (post-I1, 74 compounds; NB09 Part 4): KEGG-linked/no-reaction-in-genomes 33, fully-orphan (no KEGG) 29, biosynthesis-known/catabolism-unknown 6, only-generic-reactions 6. By class, the dark set is dominated by exactly the predicted classes: Alkaloids, Shikimates/Phenylpropanoids, Terpenoids, and Fatty acids. The dark fraction is nearly identical across sources (groundwater 53/59 = 90%, necromass 21/24 = 88%), so darkness is a chemical-class property, not a sampling-source artifact.
(Notebooks: 01_identity_resolution, 02_pathway_linkage, 02b_linkage_deepening, 02c_fb_inchikey_rematch, 03_organism_mapping, 08_synthesis, 09_deepening)
2. H1 (coverage gradient by chemical class) — not formally supported (underpowered); directional only
The 9 callable compounds are overwhelmingly pollutant-adjacent aromatics: salicylic acid, 3-hydroxybenzoic acid, 4-hydroxybenzaldehyde, phthalic acid, terephthalic acid (all Shikimates/Phenylpropanoids), plus Phenylethylamine and xanthine (Alkaloids), Abscisic acid (Terpenoid, a single 2-strain call), and lauric acid (Fatty acid, on a measured_fitness basis only — review I1). One caveat on this set: xanthine is mis-scored as carbon-catabolic — its allowlisted reaction R02107 (xanthine→urate, xanthine oxidase) is the purine pathway, which is nitrogen acquisition, not carbon catabolism, so the carbon-callable set is effectively 8, not 9 (see Limitations). The aromatic/phthalate concentration is unaffected. The apparent direction matches the prediction — callables cluster in the aromatic/phthalate subset that curated biodegradation knowledge and KEGG cover. But the pre-registered null (uniform coverage across classes) is not rejected: a χ² test on the 8 enigma_isolate_call callables by class (Shikimates 5/25, Alkaloids 2/26, Terpenoids 1/17, Fatty acids 0/10, Polyketides 0/2, AA/Peptides 0/2, mixed 0/1) gives χ²=5.07, p=0.53 (df=6); adding the single measured-fitness lauric acid (Fatty acids 1/10) does not change the verdict. With only ~9 callables across 83 compounds the design is underpowered to detect a class gradient, and the directional pattern is further confounded with annotation coverage (which classes KEGG/ModelSEED/genome_depot annotate) rather than a clean biological degradability gradient. Verdict: H1 not formally supported. The per-class Tier-0 list remains a useful descriptive enrichment-design deliverable, which does not require H1 to hold.
(Notebook: 08_synthesis)
3. H2 (cross-module modularity) — not supported beyond a shared aromatic funnel
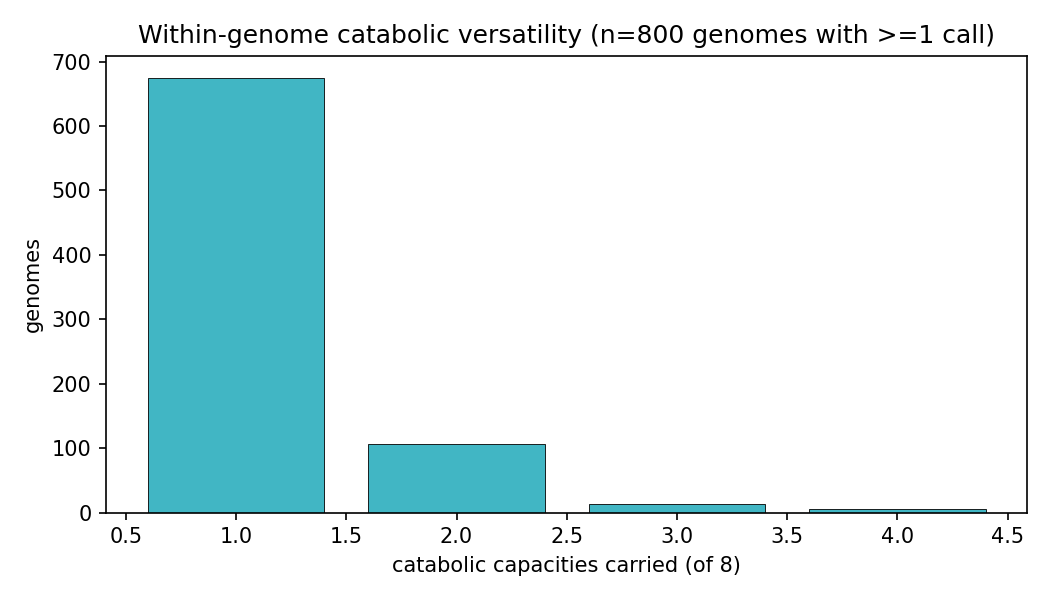
Among the 8 enigma_isolate_call capacities across genomes carrying ≥1 capacity, catabolic versatility is right-skewed (mean ~1.19, median 1, max 4 capacities per genome). NB05 first reported co-occurrence with the φ coefficient, but φ compresses toward zero when a capacity is rare (most are present in tens-to-hundreds of 3109 genomes), which can hide a real multiplicative enrichment. Review I4 (NB05b) recomputes two interpretable effect sizes per pair from the saved 2×2 counts — a Haldane-corrected odds ratio + 95% CI and the Jaccard index — with no Spark re-run.
The effect sizes sharpen but do not overturn the verdict. By pair class: within-aromatic median OR 1.12 (3/10 pairs with CI entirely > 1, median Jaccard 0.026); within-other median OR 7.43 (1/3, but driven by Haldane correction on near-zero counts); and the genuine modularity test — cross-block pairs (distinct lower pathways) — median OR 2.28 with 4/15 CI > 1 but median Jaccard ≈ 0. The one biologically real cross-block signal the OR surfaces (and φ hid) is phenylethylamine co-occurring with aromatic-funnel acids: 4-hydroxybenzaldehyde + phenylethylamine OR 2.84 (95% CI 1.49–5.40, q=0.035, n11=11); phthalic acid + phenylethylamine OR 3.37 (95% CI 1.46–7.75, q=0.071, n11=6). This is expected and mechanistically coherent, because phenylethylamine is itself an aromatic-derived substrate (deaminated to phenylacetate, then the paa/phenylacetyl-CoA route), so versatile aromatic degraders tend to carry both. Crucially the Jaccard stays ≈ 0.04 even for these enriched pairs — only ~4% of genomes with either capacity carry both — and only 25 of 3109 genomes (0.8%) carry both an aromatic and a non-aromatic capacity. Verdict: no broad cross-module modularity; the one positive signal is itself aromatic-derived, i.e. co-occurrence within the broad aromatic-catabolism phenotype, not modular co-assembly of mechanistically-distinct modules. What is supported is phylogenetic concentration — Burkholderiales dominate utilizer counts, and high-versatility genera (Polaromonas, Alcaligenes, Burkholderia, Paraburkholderia, Comamonas, Hydrogenophaga) cluster in that order.
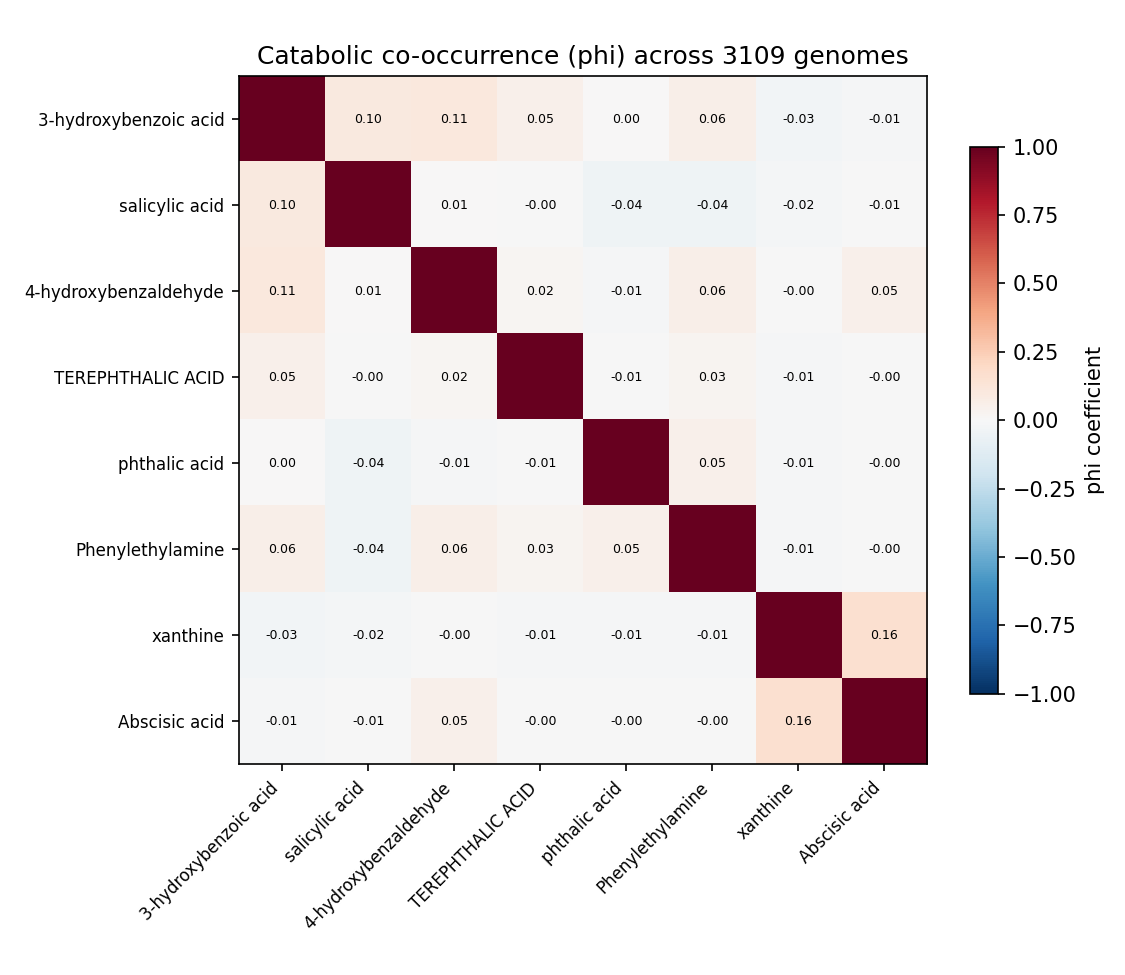
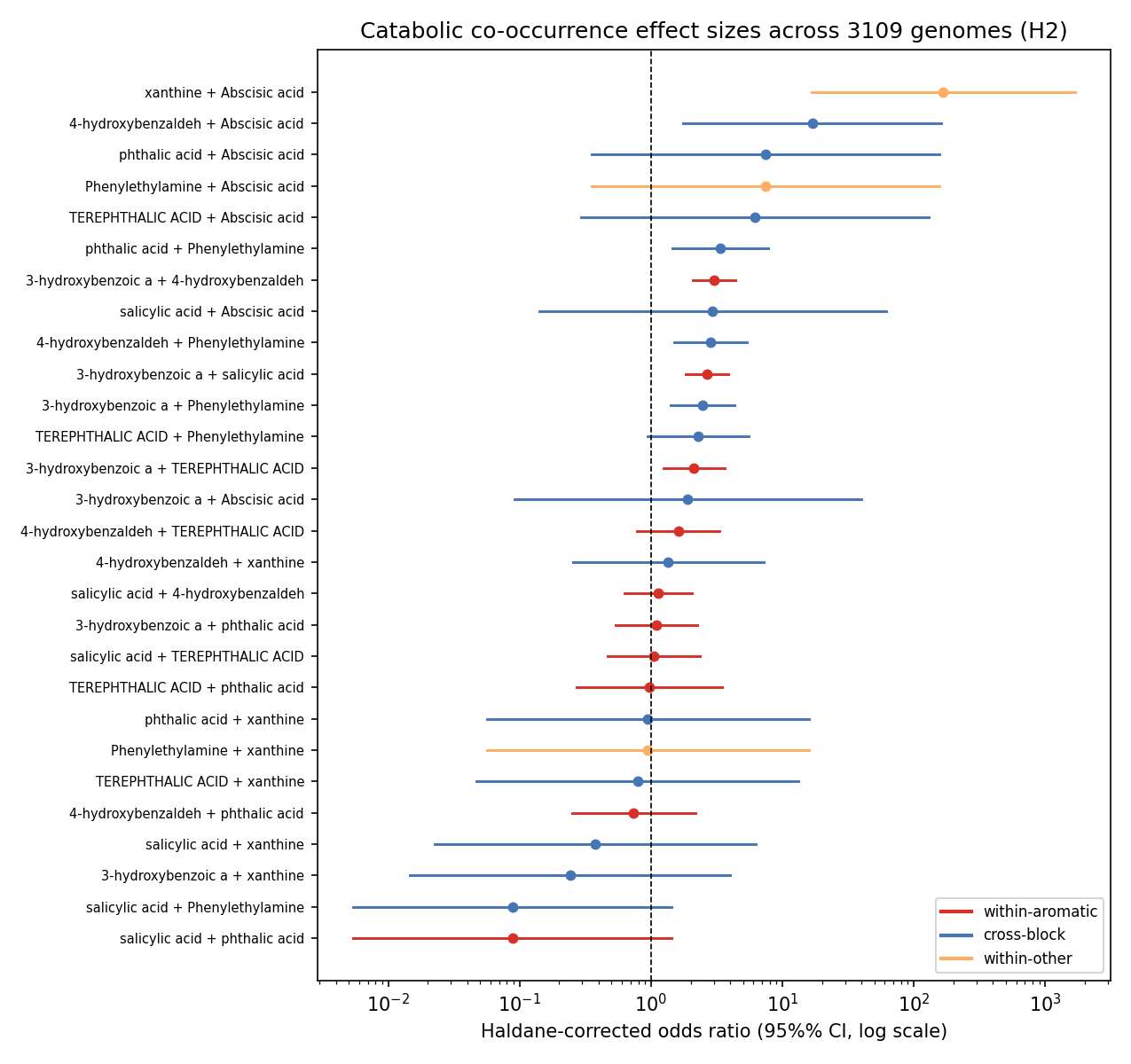
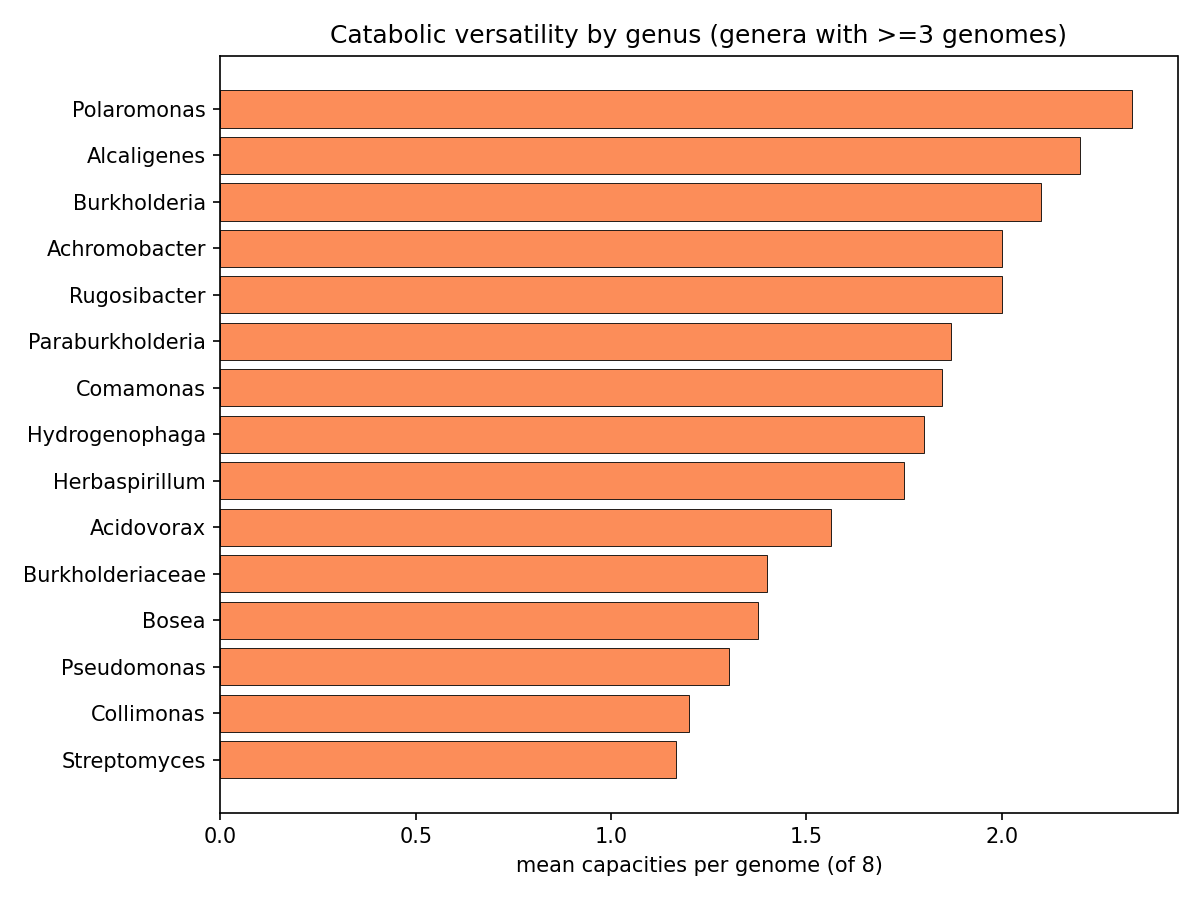
(Notebooks: 05_cooccurrence, 05b_cooccurrence_effects)
4. H3 (source-tracking: groundwater vs necromass) — untestable / confounded, reported as such
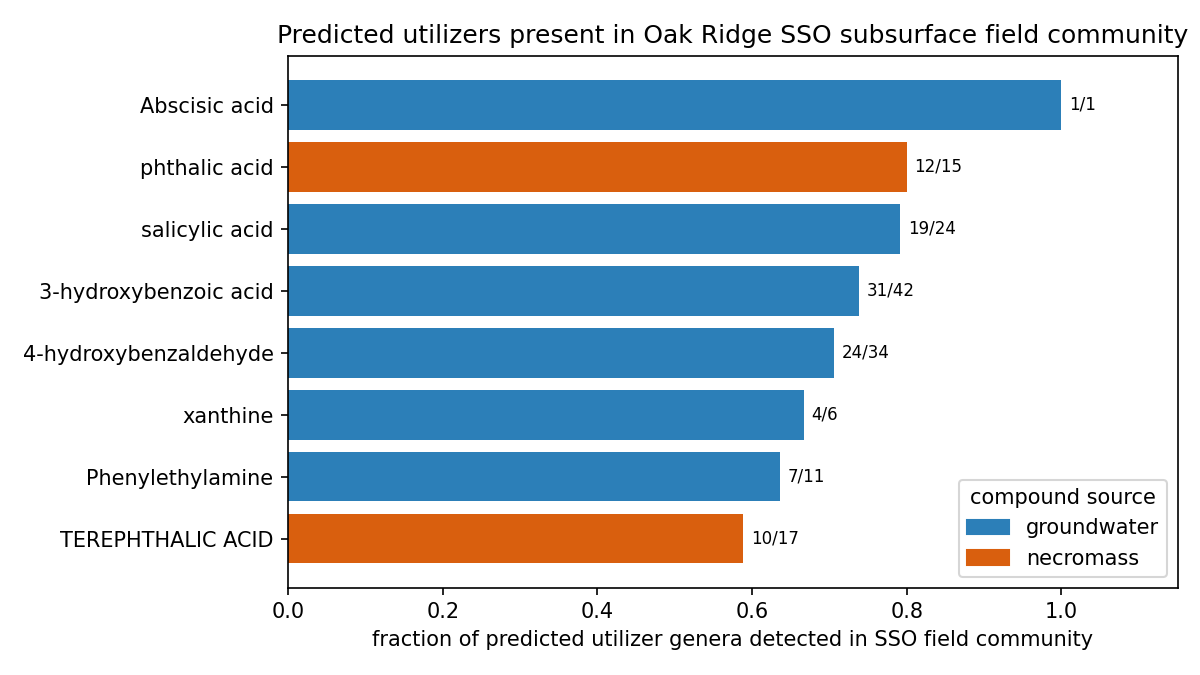
Of the 8 ENIGMA-isolate-callable compounds, only 2 are necromass-sourced (terephthalic + phthalic acid), and both are phthalate-class aromatics with Actinomycetota-heavy utilizers. (The 9th callable, lauric acid, is also necromass but has no ENIGMA-isolate utilizers and no field data, so it adds nothing to the source contrast.) Source is therefore inseparable from chemical class at n=2 — there is no honest statistical contrast to run. Rather than fabricate a confounded result, NB07 was reframed as a straight SSO field-occurrence atlas (Zhou Lab 16S, enigma_coral bricks): 62 of the implicated utilizer genera are observed in the SSO field at genus resolution, with top field prevalences ~0.7–0.9 for the aromatic utilizers (e.g. 3-hydroxybenzoic-acid utilizers at 0.90 field prevalence).
(Notebook: 07_environmental_atlas)
5. Deliverables (a) + (b): tier-stratified isolate predictions, phylogenetically concentrated
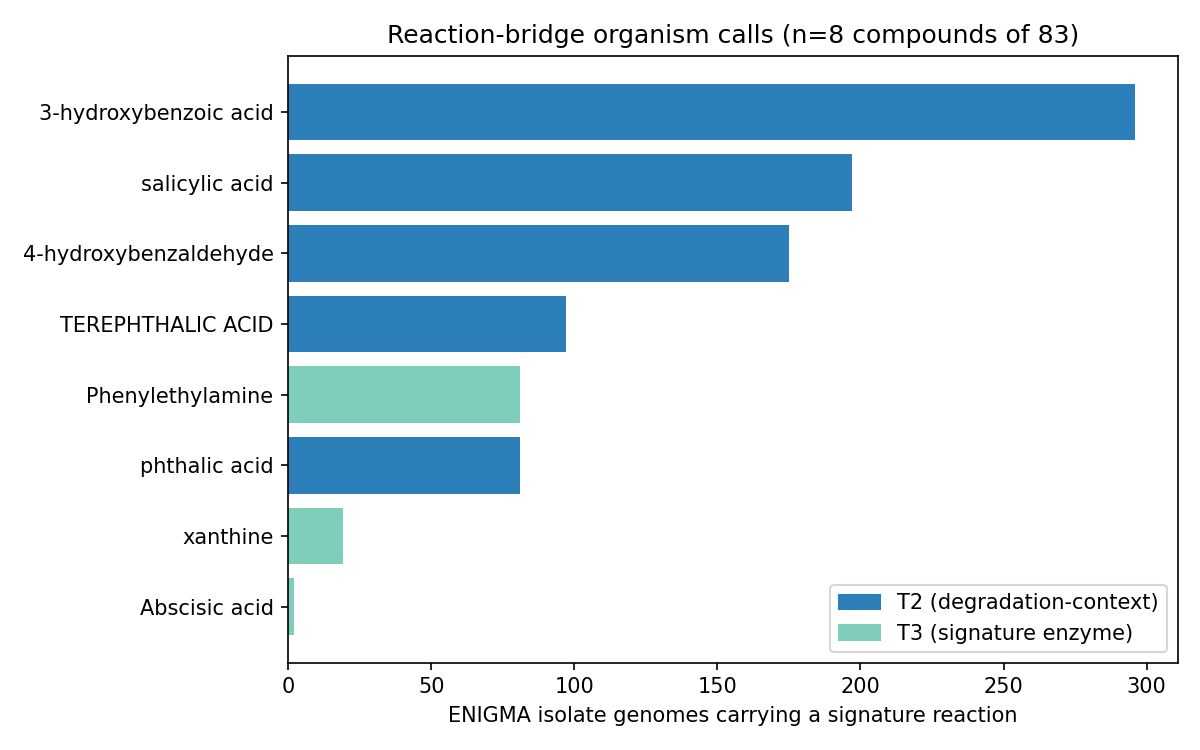
Deliverable (a) — 569 ENIGMA-isolate utilizer prediction rows across the 8 ENIGMA-isolate-callable compounds (lauric acid, callable only on measured fitness, has no ENIGMA-isolate rows). The aromatics carry the bulk: salicylic acid 129 strains, 3-hydroxybenzoic acid 127, 4-hydroxybenzaldehyde 125; terephthalic acid 34; phthalic acid 36; Phenylethylamine 28; xanthine 13; Abscisic acid 2. (The "34 all high-certainty" for terephthalic acid is a single-reaction-signature artifact, not a strength — see below and Limitations.)
Deliverable (b) — 494 strain placements on the GTDB taxonomy (359 distinct strains), each carrying a tier × certainty score: 64 high-certainty (gene-complete pathway, Tier 2), 387 medium (Tier 2 pathway), 43 medium (Tier 3 signature enzyme). Utilizers concentrate in Pseudomonadota / Burkholderiales, with Pseudomonadales and Sphingomonadales contributing to specific compounds (e.g. Sphingomonadales 47 strains for 4-hydroxybenzaldehyde).
H4 verdict (tier-stratified, phylogenetically concentrated isolate predictions per compound): partially supported — strongly for the 8 ENIGMA-isolate-callable compounds, null for the other 75. The 8 callable-with-isolate compounds each yield a tier-stratified prediction set that concentrates phylogenetically (Pseudomonadota/Burkholderiales, with compound-specific Sphingomonadales/Pseudomonadales contributions), exactly as H4 predicted. The remaining 75 are Tier 0 with no isolate-level placement, so H4 is null there. (Lauric acid, the 9th callable, qualifies only on measured RB-TnSeq fitness in a reference bacterium and contributes no ENIGMA-isolate phylogenetic prediction, so it sits outside both arms.)
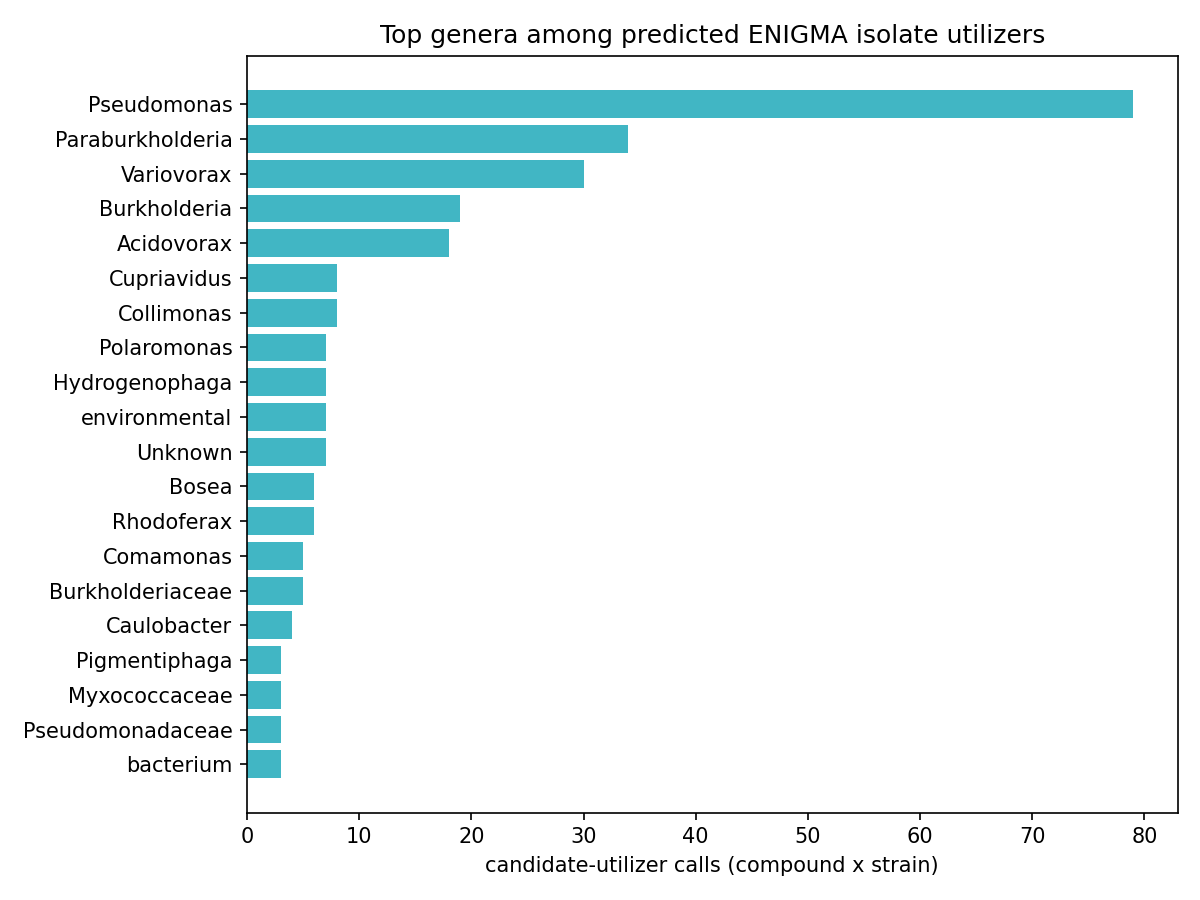
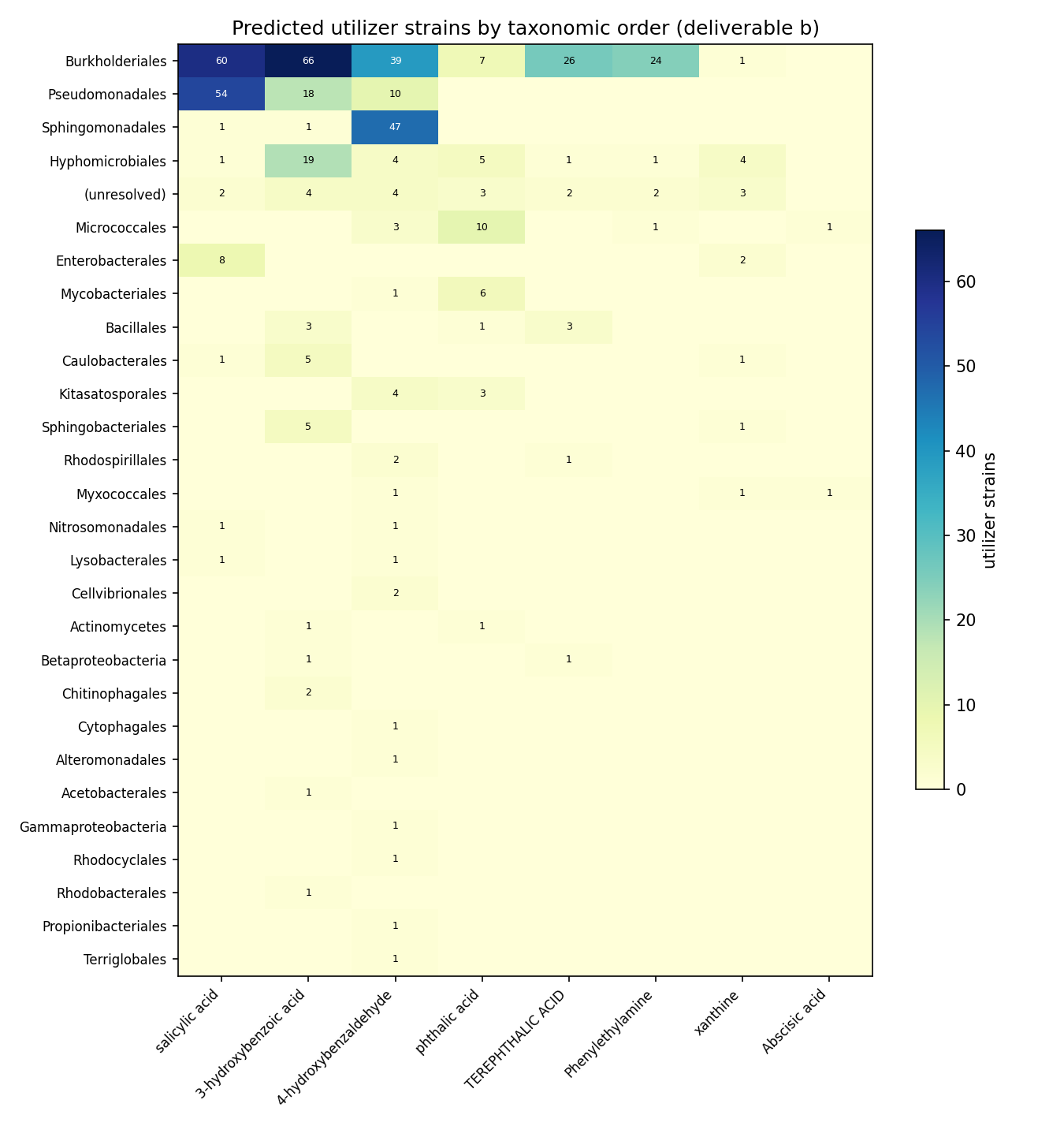
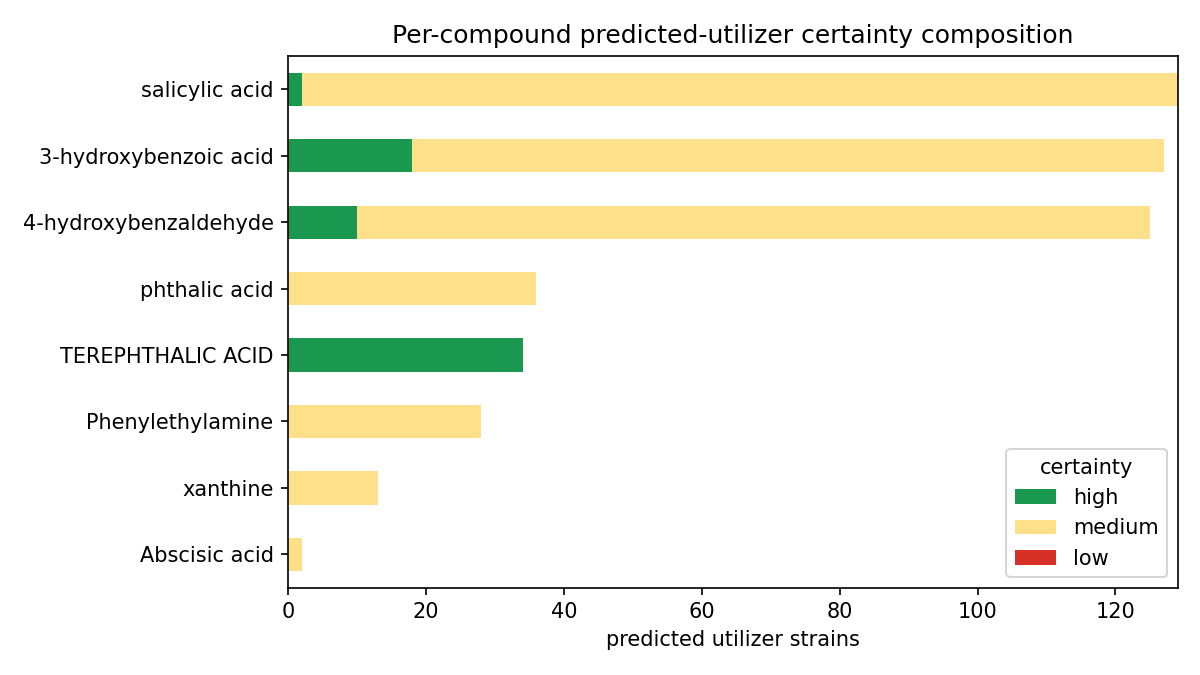
(Notebooks: 04_enigma_utilizers, 06_phylo_maps)
6. Deliverable (c), global arm: a cross-environment abundance atlas for the 86 implicated genera
Beyond the local SSO field atlas, the implicated utilizer genera were placed across global environments — terrestrial/freshwater (NMDC, kbase.nmdc_arkin) and marine (Planet Microbe, as a contrast). This is a biome-abundance proxy, not catabolic activity: no environmental dataset measures the census compounds, so genus abundance indicates where the organisms live, not where the compounds are degraded.
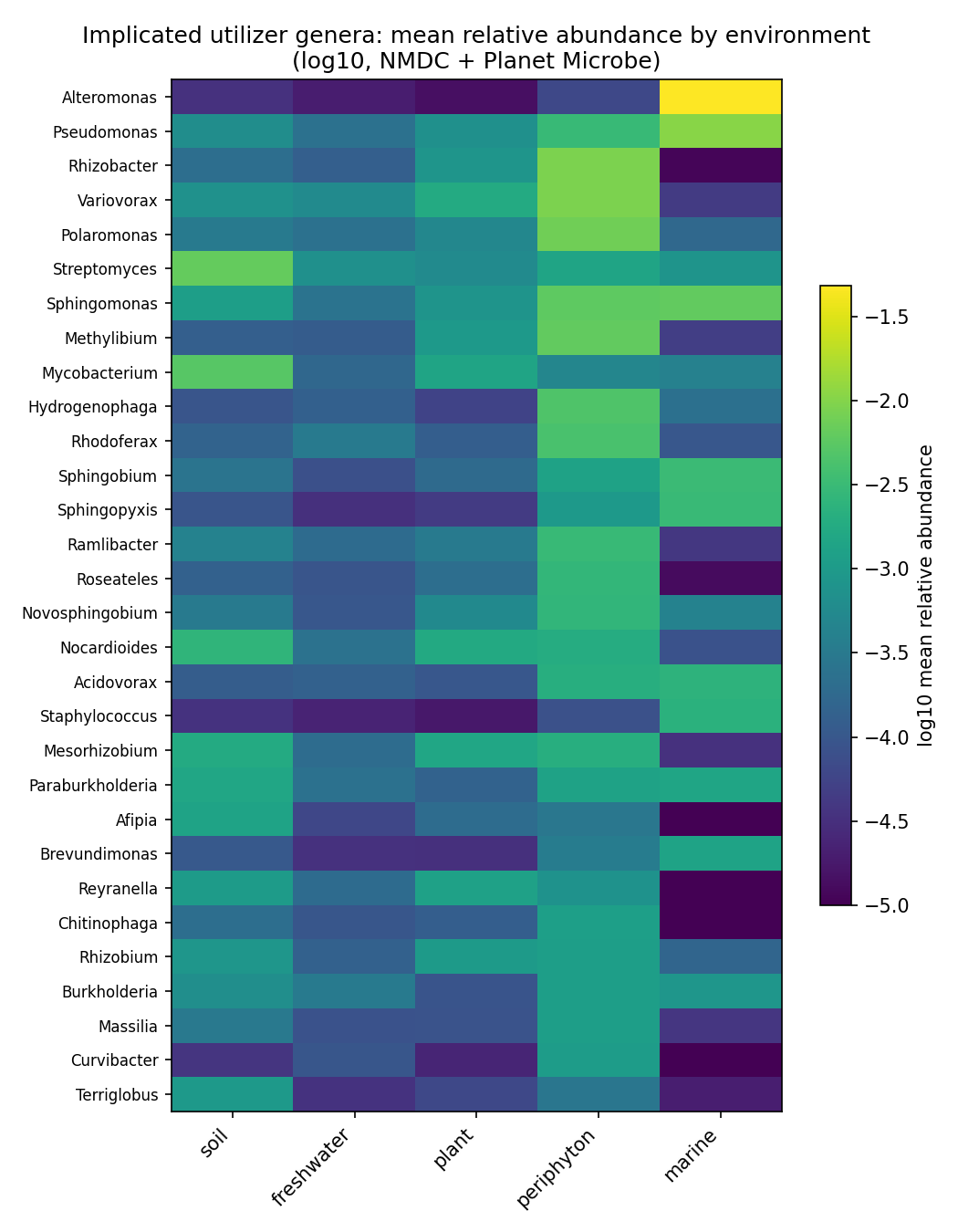
NMDC scale: 3825 taxonomy-bearing metagenomes (denominator = covstats files with taxonomy), 83/86 genera detected in 1719 metagenomes, 99% sample-labeled via two independent ontologies (ENVO MIxS triad + GOLD ecosystem path). Macro-environment distribution: soil 2260, freshwater 723, periphyton 472, plant 119, sediment 42.
Soil-vs-freshwater abundance contrast (exploratory — see Limitations) recovers textbook biogeography: soil-enriched genera are classic soil taxa (Mycobacterium log2 +5.09, Terriglobus +5.29, Nitrobacter +4.79, Afipia, Streptomyces, Nocardioides, Mesorhizobium), and freshwater-enriched genera are aquatic Betaproteobacteria (Cellvibrio log2 −2.19, Curvibacter, Rhodoferax, Comamonas, Acidovorax). The newly surfaced periphyton class (freshwater biofilms: epilithon/epipsammon/epiphyton) is a strong reservoir — Burkholderiales/Comamonadaceae (Rhizobacter, Variovorax, Polaromonas, Methylibium, Sphingomonas, Hydrogenophaga) at ~96–97% prevalence and mean relative abundance ~0.005–0.009.
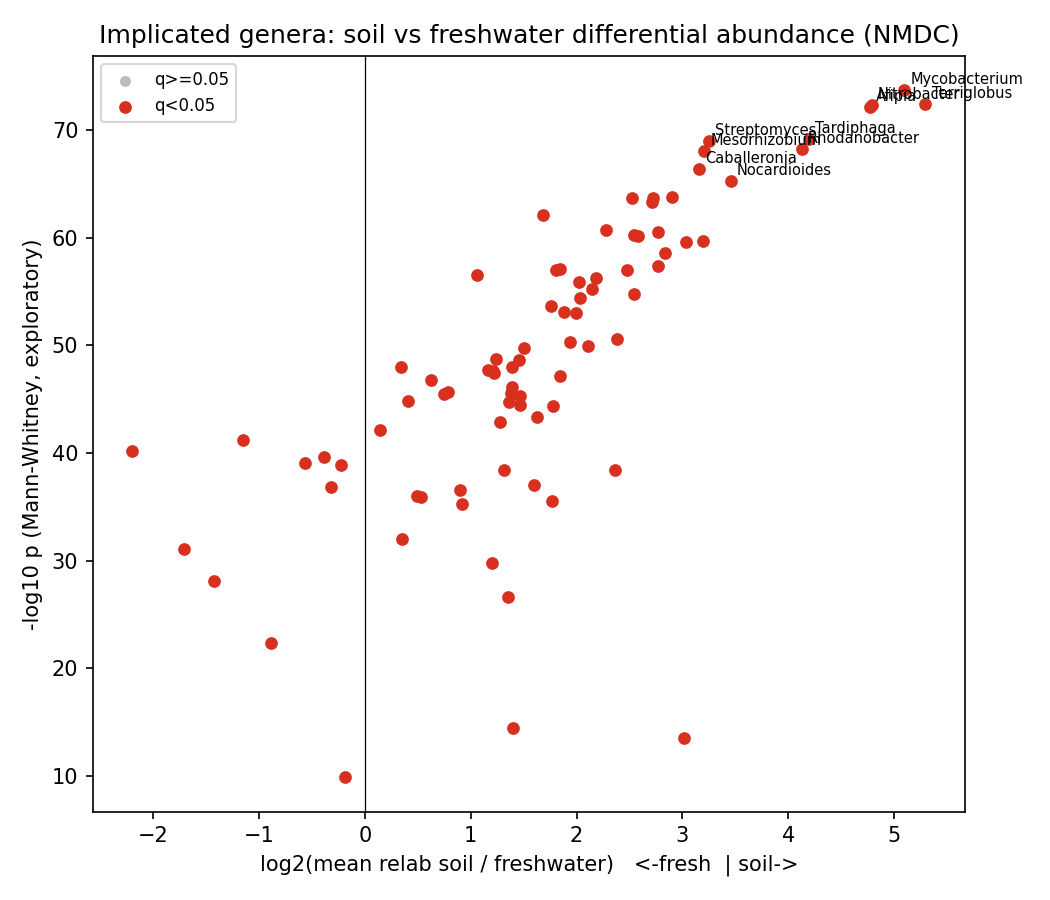
Label-free outlier discovery (the most defensible signal, robust to label noise): top genus×sample relative-abundance spikes occur in periphyton (Nocardioides 0.43 in epipsammon, Hydrogenophaga 0.28 in epiphyton) and soil (Mycobacterium 0.22). Outliers peak in periphyton (34 genera) and soil (32).
Marine (Planet Microbe, 302 runs): 68/68 listed genera show positive abundance, but marine is mostly a negative biome contrast — terrestrial/freshwater genera sit at ~1e-3 to 1e-4 in open ocean. Genuine marine members are the exception (Alteromonas 0.048 in 240/302 runs, prevalence 0.79; cosmopolitan Pseudomonas 0.011, Sphingomonas 0.0063).
(Notebook: 07b_environmental_atlas_global)
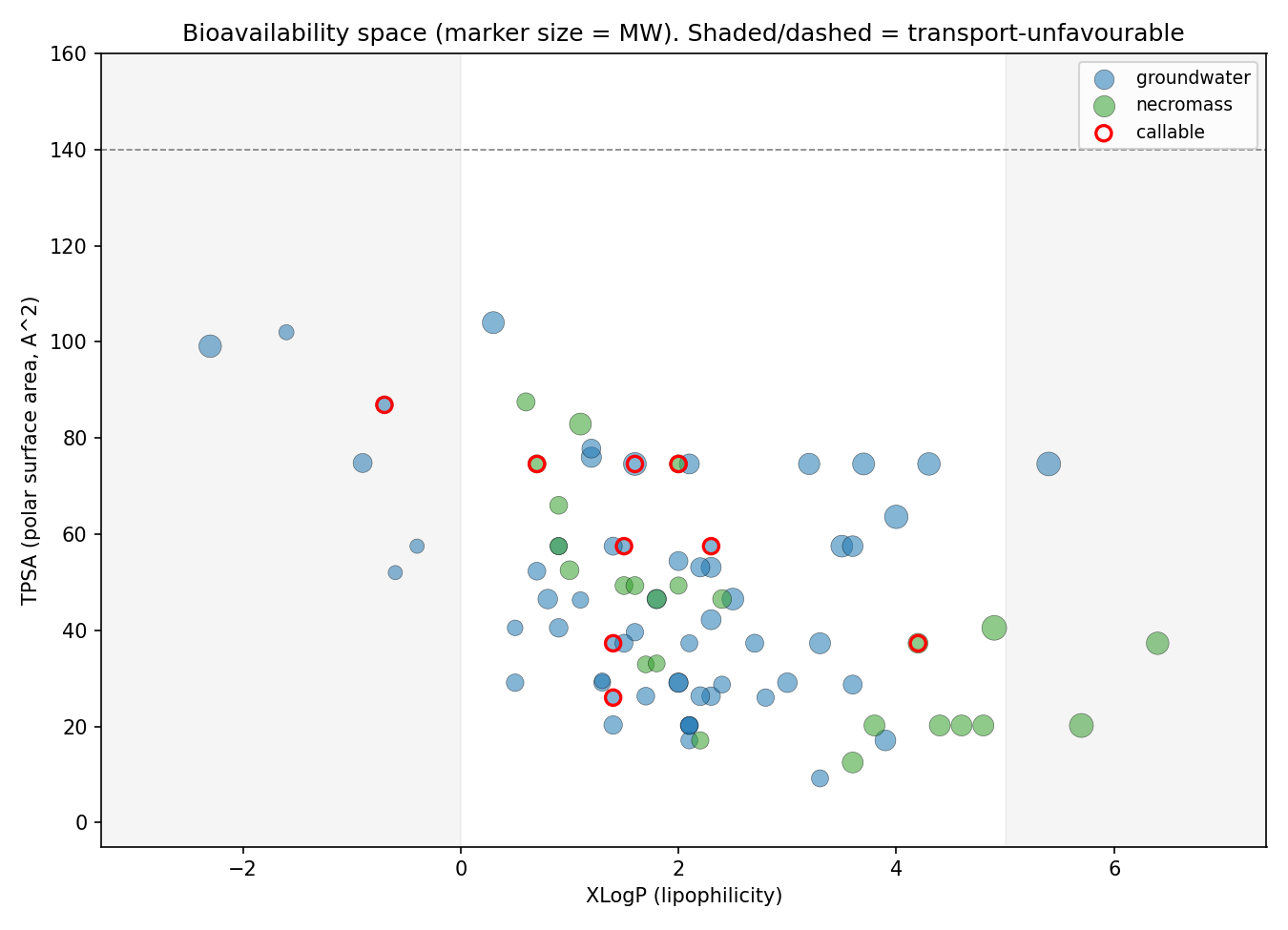
7. Bioavailability/physicochemistry is a ceiling on the atlas: callable compounds are smaller and simpler (directional, underpowered)
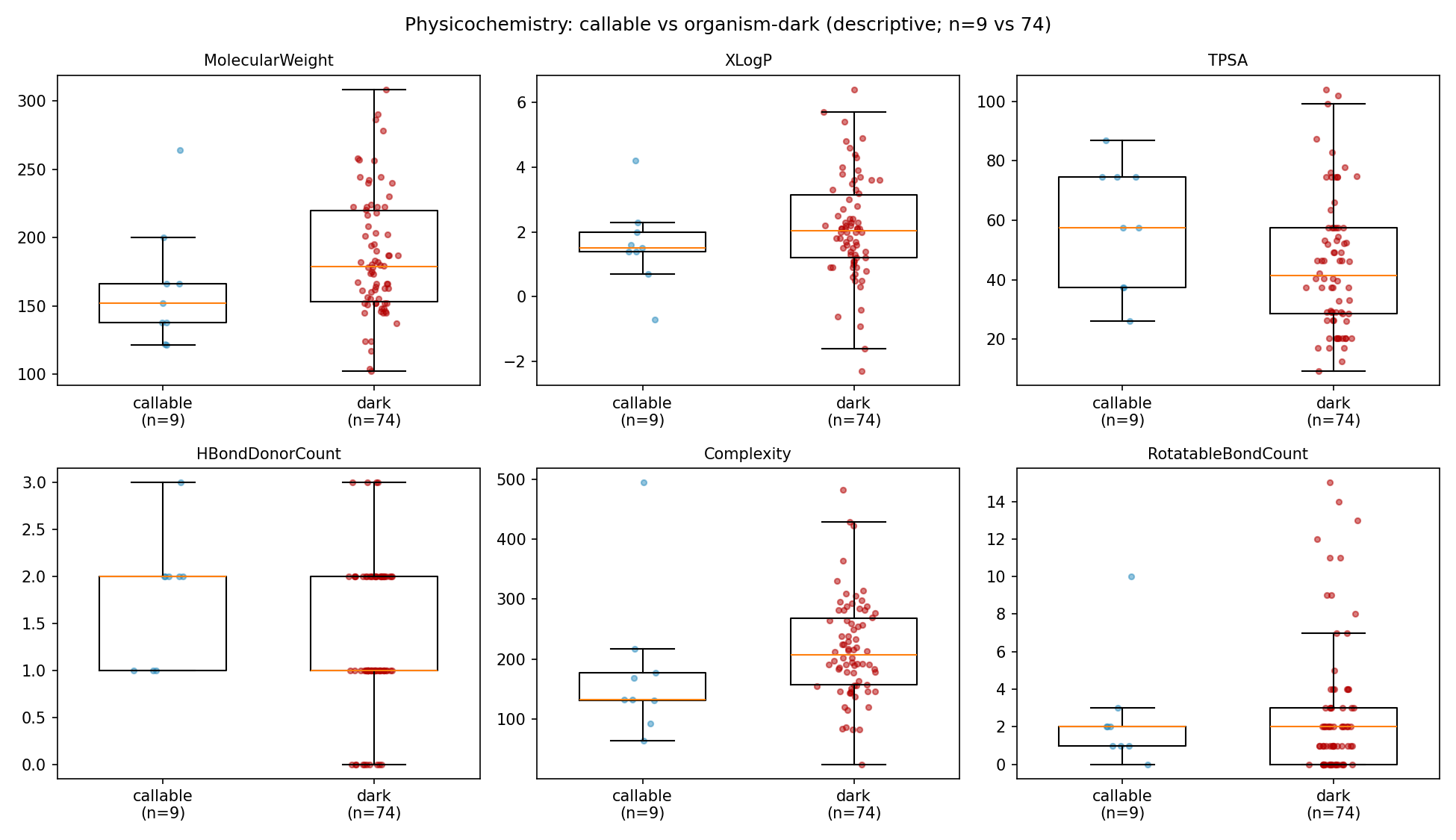
NB09 Part 1 resolves PubChem physicochemical descriptors for all 83 compounds and contrasts callable vs dark. With only n=9 callable this is directional, not inferential (Mann–Whitney, reported as direction + uncorrected p). Callable compounds are consistently smaller and structurally simpler than dark ones: median Complexity 133 vs 207 (p=0.034), MolecularWeight 152 vs 179 (p=0.066), HeavyAtomCount 11 vs 13 (p=0.057), with directionally higher polarity (TPSA 57 vs 41, H-bond donors 2 vs 1). The honest reading is that this is at least as much an annotation-coverage ceiling as a biological-bioavailability one — simple, common, pollutant-adjacent aromatics are exactly the molecules KEGG/ModelSEED/genome_depot annotate, so "callable" tracks structural simplicity partly because the knowledge base does. Notably there is no physicochemical separation between groundwater and necromass compounds (all contrasts p>0.14), reinforcing that source does not predict chemistry here.
(Notebook: 09_deepening)
8. The callable phenotype is a specialist clade trait, not a portable generalist module set
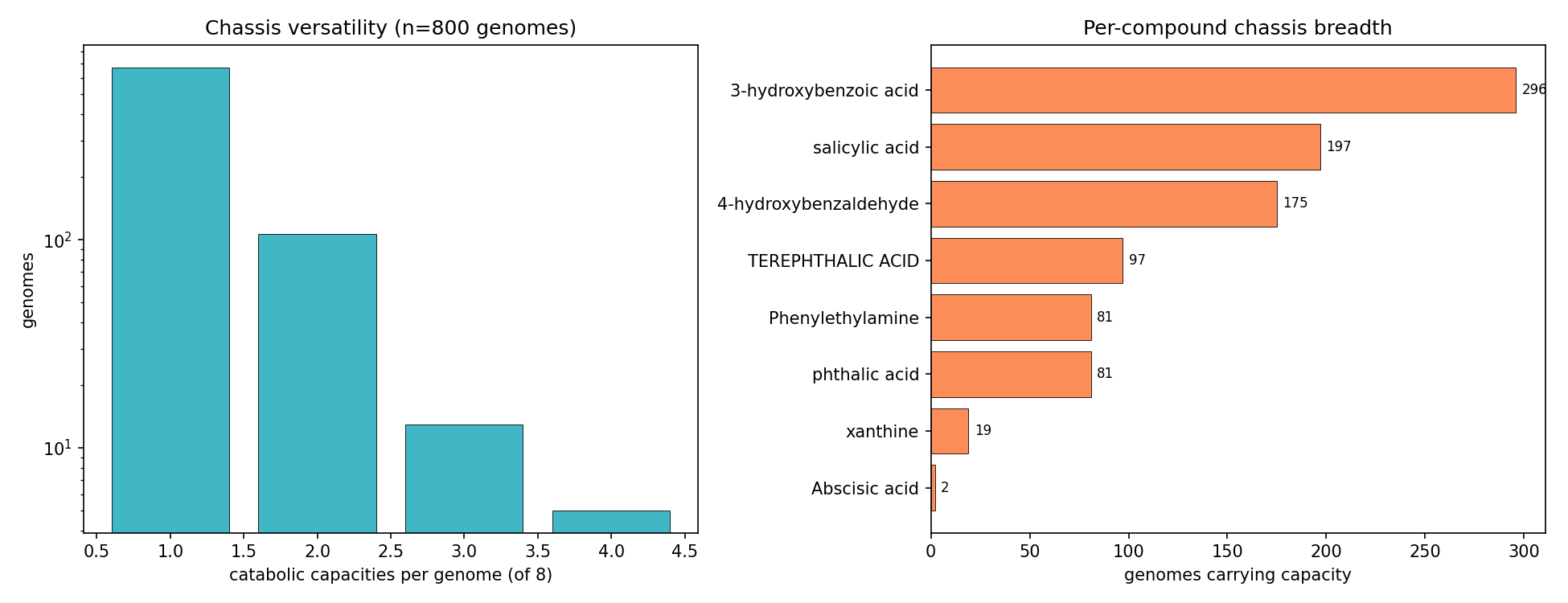
NB09 Part 2 transposes the deliverable to genomes. Of genomes carrying ≥1 of the 8 aromatic/alkaloid capacities, 675 are specialists (exactly 1 capacity) and only 18 are generalists (≥3; max 4). Generalist chassis concentrate in Paraburkholderia (5), Burkholderia (4), Hydrogenophaga (2) and scattered Burkholderiaceae — the same clade that dominates the versatility ranking, confirming versatility is a clade trait, not a widely portable module. All callable evidence is catabolic-direction by construction of the NB03 filter (846 Tier-2 pathway + 102 Tier-3 signature genome-compound calls; biosynthetic-only signatures are excluded and land in the dark set). Part 3 (per-clade conservation) shows compound-specific clade specialization rather than a shared generalist toolkit. These conservation fractions are denominated over depot genomes that already carry some catabolic call — not a census of all genomes of each genus — so they describe within-called-set specialization, not absolute prevalence: e.g. Castellaniella and Hylemonella carry 3-hydroxybenzoic-acid capacity in ~100% of such genomes, Sphingomonads (Novosphingobium/Sphingobium) carry 4-hydroxybenzaldehyde capacity at ~92–100%, Paenarthrobacter carries phthalic-acid capacity at 100%, and Comamonas spans both 3-hydroxybenzoate (92%) and 4-hydroxybenzaldehyde (85%). Capacity breadth across the chassis is led by 3-hydroxybenzoic acid (296 genomes, 53 genera) and salicylic acid (197 genomes, 28 genera); Abscisic acid is a 2-genome edge case.
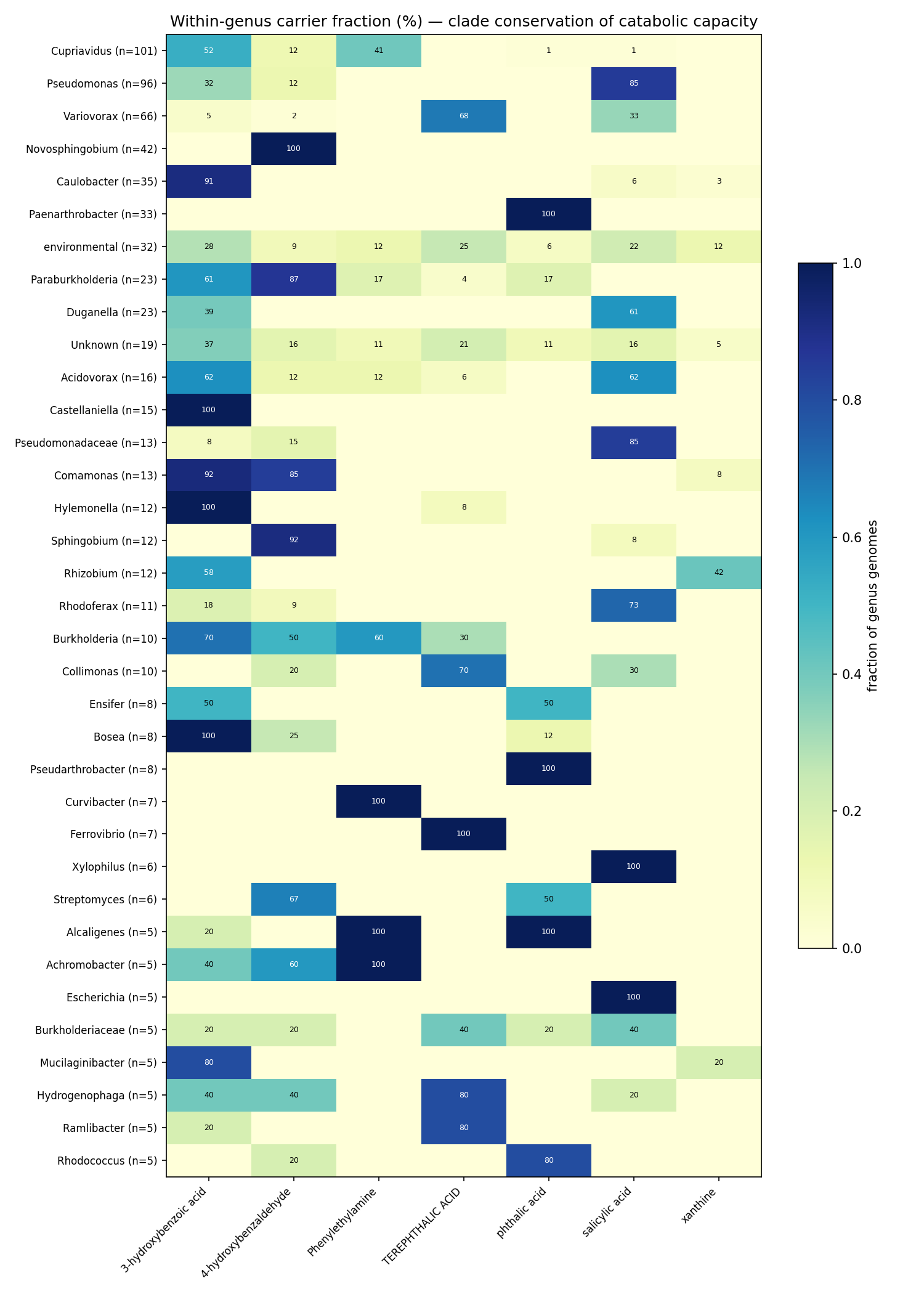
(Notebook: 09_deepening)
9. The dark set has structure: 6 biosynthesis-known compounds are MIBiG-consult targets, not true orphans
NB09 Part 4 taxonomizes the 74 organism-dark compounds (post-I1) into four buckets: 33 KEGG-linked but no reaction in any queried genome, 29 fully orphan (no KEGG link at all), 6 biosynthesis-known/catabolism-unknown, and 6 only-generic-reactions. The 6 biosynthesis-known compounds — Tyramine, guanidineacetic acid, cinnamic acid, caffeic acid, palmitic acid, farnesol — have annotated biosynthetic-direction signatures but no catabolic call, which is exactly the profile to triage against MIBiG/biosynthetic literature before committing to discovery enrichment (flagged as an external consult; MIBiG was not queried in BERDL). The 29 fully-orphan compounds (no KEGG link) are the hardest discovery targets and skew necromass-heavy (13/24 necromass vs 16/59 groundwater are orphan). This per-bucket structure is the operational refinement of the headline gap: it ranks the 74 dark compounds by why they are dark and therefore by how to attack them.
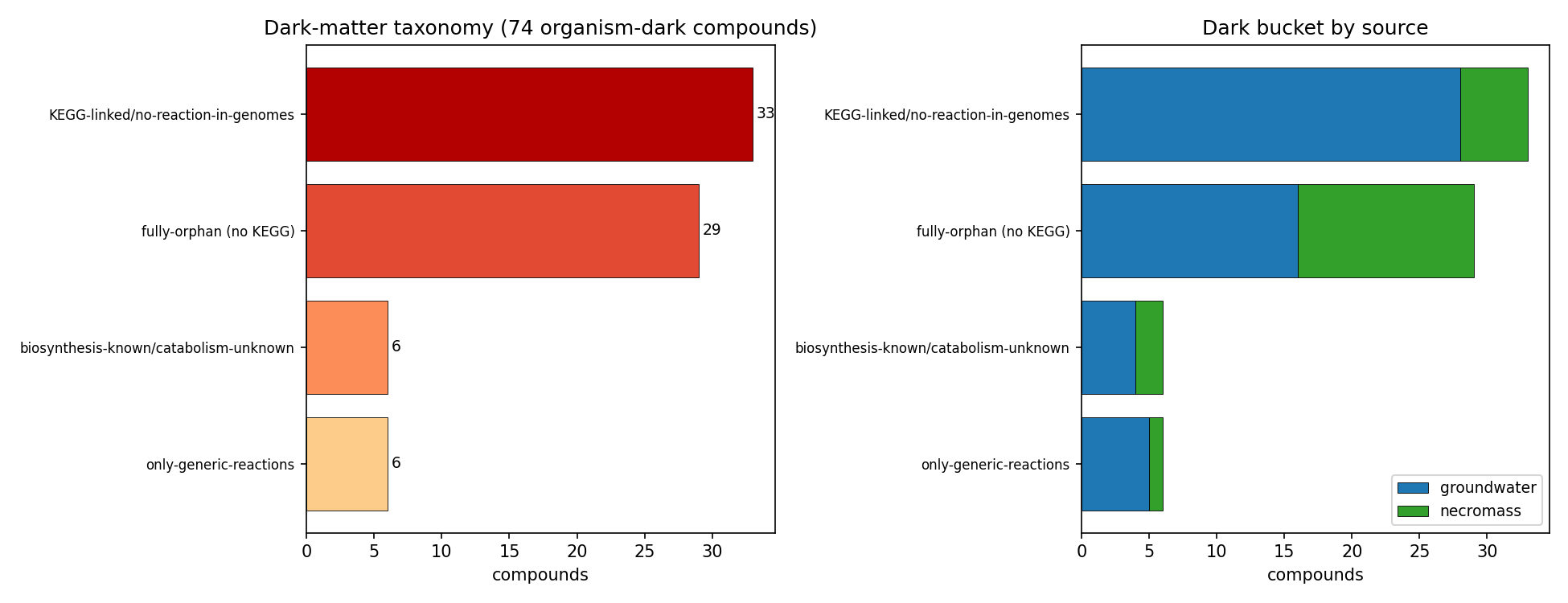
(Notebook: 09_deepening)
Results
The callable-compound table (the table a wet-lab planner reads)
| Compound | Source | NPC pathway | Best tier | n strains (a) | n high-cert | n genera (b) | n field genera (c) | top field prev |
|---|---|---|---|---|---|---|---|---|
| salicylic acid | groundwater | Shikimates/Phenylpropanoids | T2_3_reaction | 129 | 2 | 24 | 20 | 0.86 |
| 3-hydroxybenzoic acid | groundwater | Shikimates/Phenylpropanoids | T2_3_reaction | 127 | 18 | 42 | 33 | 0.90 |
| 4-hydroxybenzaldehyde | groundwater | Shikimates/Phenylpropanoids | T2_3_reaction | 125 | 10 | 34 | 25 | 0.86 |
| phthalic acid | necromass | Shikimates/Phenylpropanoids | T2_3_reaction | 36 | 0 | 15 | 12 | 0.75 |
| terephthalic acid | necromass | Shikimates/Phenylpropanoids | T2_3_reaction | 34 | 34 | 17 | 10 | 0.67 |
| Phenylethylamine | groundwater | Alkaloids | T2_3_reaction | 28 | 0 | 11 | 7 | 0.61 |
| xanthine † | groundwater | Alkaloids | T3_kegg | 13 | 0 | 6 | 4 | 0.75 |
| Abscisic acid | groundwater | Terpenoids | T2_3_reaction | 2 | 0 | 1 | 1 | 0.02 |
| lauric acid ‡ | necromass | Fatty acids | T1_measured | 0 | 0 | 0 | 0 | — |
† xanthine is mis-scored: its allowlisted reaction R02107 (xanthine→urate) is the purine nitrogen pathway, not carbon catabolism. The carbon-callable set is effectively 8 (see Limitations). The NB03 carbon allowlist has since been corrected to exclude R02107; the committed tables still list xanthine because they predate that fix and were not regenerated.
‡ lauric acid is callable on a measured_fitness basis only (review I1 / NB02c): it has a Tier-1 measured carbon-source fitness experiment in the Fitness Browser whose organism is a reference bacterium, not an ENIGMA isolate — so it carries no ENIGMA-isolate strains/genera/field rows and does not appear in deliverable (a).
Headline numbers
| Metric | Value |
|---|---|
| Compounds in census | 83 |
| Structure-resolved (InChIKey) | 83 |
| KEGG-linked | 54 |
| Callable (isolate call OR measured fitness) | 9 (8 enigma_isolate_call + 1 measured_fitness) |
| Organism-dark (discovery targets) | 74 (89%) |
| Utilizer strains placed (b) | 359 (64 high-certainty) |
| Utilizer genera in SSO field (c) | 62 |
| NMDC taxonomy-bearing metagenomes (global c) | 3825 |
| Implicated genera detected in NMDC | 83/86 (1719 metagenomes) |
| Planet Microbe runs / genera positive | 302 / 68 of 68 |
Interpretation
The census behaves as a knowledge product over natural-product secondary metabolites should: catabolic knowledge in the queried resources is real and deep for the aromatic/phthalate subset and absent for most alkaloids and terpenoids. Six of the eight callable compounds route through well-characterized aromatic catabolism (salicylate, the hydroxybenzoates/-aldehyde, and the two phthalates converging on protocatechuate/catechol and the β-ketoadipate pathway), which is why their utilizers are numerous and phylogenetically concentrated; the remaining two do not — phenylethylamine enters the phenylacetyl-CoA (paa) ring-cleavage route, and xanthine is a purine (nitrogen) pathway mis-included here. The 75 dark compounds are not a failure of method — they are the deliverable: they name where genetic determinants of carbon use are not linkable in these resources and where enrichment is the candidate route to discovery.
The environmental atlas adds where to look, with an honest ceiling. Because no environmental dataset measures the compounds, the global atlas reports biome occupancy of the implicated genera, not catabolic flux. The signal is biologically coherent (soil generalists in soil, aquatic Betaproteobacteria in freshwater, a Comamonadaceae periphyton reservoir, terrestrial taxa rare in open ocean), which validates the taxonomic/abundance pipeline — that genus calls and ENVO/GOLD labels are sound — but it does not validate the upstream compound→pathway→organism inference, and it cannot claim that any genus degrades a census compound in any sampled environment.
Literature Context
- The aromatic convergence onto the β-ketoadipate / protocatechuate–catechol funnel is the canonical bacterial route for hydroxybenzoates, salicylate, and phthalates (Harwood & Parales, Annu. Rev. Microbiol. 1996), consistent with this census finding that the six callable aromatics share one lower pathway and therefore co-occur within the aromatic block. Phenylethylamine instead routes via amine oxidation to phenylacetate and the phenylacetyl-CoA (paa) pathway (Hanlon et al., Microbiology 1997) — mechanistically separate, which is why its cross-block co-occurrence signal (Finding 3) is not part of the β-ketoadipate funnel.
- Burkholderiales / Comamonadaceae dominance is best supported specifically for phthalate/terephthalate catabolism (Pérez-García et al. 2025, above), matching the versatility ranking (NB05). The freshwater-biofilm/periphyton enrichment of this clade is reported here primarily on the project's own NB07b abundance data (~97% prevalence in periphyton samples) rather than a single comparative-microbiology citation, and should be read as this project's observation pending a targeted literature anchor.
- Terephthalate/phthalate catabolism is the best-characterized necromass aromatic here — terephthalate proceeds via terephthalate dioxygenase to protocatechuate, concentrated in Pseudomonadota (Ideonella/Comamonas) and actinobacterial degraders (Pérez-García et al., Microbiol. Mol. Biol. Rev. 2025) — consistent with the phthalate call set (though the terephthalic "all-high" certainty is a single-reaction-signature artifact, not strong evidence; see Limitations).
Novel Contribution
What this census adds beyond what any single database states: (1) a unified, tier-stratified linkage from 83 named compounds → structures → pathways → ENIGMA isolate strains → GTDB phylogeny → SSO field occurrence → global biome abundance, with the gap (Tier 0) treated as a first-class result; (2) a quantified dark-fraction (89%, 74/83) with per-class, per-reason structure to drive enrichment prioritization; (3) a periphyton-resolved abundance reservoir for the implicated genera that bulk-environment labels obscure.
Limitations
- The soil-vs-freshwater enrichment p/q-values are exploratory and not calibrated. Each metagenome is treated as an independent observation in a rank test over compositional, zero-inflated relative abundances; with thousands of non-independent samples this inflates significance massively (all 83 genera reach q<0.05, many at q~1e-70). The direction and rank of the contrast are trustworthy and biologically sensible; the p-values are not and should not be quoted as calibrated significance. The label-free outlier mode (Arm B) is the more defensible discovery signal.
- Abundance ≠ activity. No environmental dataset measures the census compounds; the entire global atlas is a biome-occupancy proxy. A genus being enriched in soil does not mean it degrades the compound there.
- H3 is genuinely untestable with these compounds (n=2 necromass callables, fully confounded with phthalate chemistry) — reported as such rather than forced.
- Catabolic-direction filter dependence. The 8
enigma_isolate_callcallables rest on a genome-prevalence-<10% signature-reaction filter that keeps a reaction only if it is catabolic for the compound (KEGG degradation map membership or a 3-reaction curated allowlist). A different filter would move the callable/dark boundary; the dark fraction is conditional on this choice. The 9th callable (lauric acid) is on an independentmeasured_fitnessbasis and is not subject to this filter. - Callable-vs-dark physicochemical contrasts are underpowered. With only n=9 callable, the NB09 Part 1 contrasts (callable compounds smaller/simpler) are directional only, reported with uncorrected Mann–Whitney p-values; they should be read as descriptive, not as calibrated significance.
- Xanthine is a category error in a carbon census. Its allowlisted reaction R02107 (xanthine→urate, xanthine oxidase) is the purine pathway, i.e. nitrogen acquisition, not carbon catabolism (Huynh & Stewart, Adv. Microb. Physiol. 2023; Newell et al., J. Bacteriol. 2022). A bacterial carbon route for purines exists but is a distinct anaerobic gene cluster this project does not score. The carbon-callable set is therefore effectively 8 (of the 9 callable). R02107 has now been removed from the carbon allowlist in
build_nb03.py; the committed deliverable tables still include xanthine because they were not regenerated after the fix, but a re-run of NB03→NB04→NB08 would drop it. - Resource-darkness ≠ scientific darkness. "Organism-dark" means not linkable via the queried BERDL/curated resources, not unknown to science. Class-level catabolic literature exists for monoterpenes (Marmulla & Harder, Front. Microbiol. 2014) and alkaloids such as nicotine (Huang et al., Front. Microbiol. 2020); NB02b's zero literature-rescues reflect a PubMed-title-only screen, not absence of evidence. A PaperBLAST/abstract-level pass would likely reclassify part of the dark set.
- "High-certainty" is not comparable across compounds.
sig_completenessis the fraction of each compound's own signature reactions a genome carries, so a single-reaction signature (terephthalic acid, 1 required reaction) trivially scores 1.0 ("high") for any carrier, while a 3-reaction signature (phthalic acid) cannot. The "terephthalic 34/34 high" headline is therefore the weakest completeness call, not the strongest. Read certainty as the rawn_sig_carried / n_required(reported inphylo_utilizer_map.tsv), not the normalized fraction. - Marine arm is small and gene-blind (302 PM runs; presence/abundance only), suitable only as a negative biome contrast.
- The pangenome↔ENIGMA taxonomic bridge is genus-level at best; isolate-specific transfer of pangenome Tier-2 reconstructions is avoided in favor of direct genome_depot annotation.
Future Directions
- Wet-lab the dark set first, triaged by bucket. The 74 organism-dark compounds are discovery-mode enrichment targets, now ranked by why they are dark (NB09 Part 4): start the hardest 29 fully-orphan (no-KEGG) compounds — especially the necromass-heavy alkaloids/terpenoids — with anonymous community enrichment + metagenomics; treat the 6 biosynthesis-known compounds (Tyramine, guanidineacetic acid, cinnamic acid, caffeic acid, palmitic acid, farnesol) as a separate MIBiG/biosynthetic-literature consult before committing wet-lab effort.
- Promote Tier 5→3 via literature mining. Targeted PaperBLAST/PubMed mining for alkaloid/terpenoid catabolic enzymes, searched back into the genomes, would convert some dark compounds to callable without new experiments.
- Calibrate the environmental contrast properly. Replace the per-sample rank test with a study-aware mixed model (or sample-level permutation respecting study structure) to get defensible enrichment statistics rather than the current exploratory ranking.
- Periphyton-sited enrichment. The Comamonadaceae periphyton reservoir suggests freshwater-biofilm inocula for the aromatic-utilizer enrichments.
Data
Sources
| Collection | Tables Used | Purpose |
|---|---|---|
| PubChem (external) | PUG-REST | Name → CID → InChIKey/SMILES + KEGG/ChEBI/ModelSEED cross-refs (identity resolution) |
| ModelSEED biochemistry | compound/reaction/enzyme | Compound → reaction → enzyme linkage (Tier 2/3) |
kbase_ke_pangenome |
functional annotations (KEGG/EC/eggNOG) | Enzyme presence across GTDB species pangenomes; null denominator (3109 genomes) |
kescience_fitnessbrowser |
RB-TnSeq carbon-source experiments | Measured utilization (Tier 1 channel) |
enigma_genome_depot_enigma |
browser_protein↔_kegg_reactions/_kegg_orthologs/_ec_numbers, browser_gene→browser_genome→browser_strain→browser_taxon |
Catabolic annotations directly on ENIGMA isolate proteins; isolate→strain→NCBI-taxid crosswalk (deliverables a, b) |
enigma (SSO field) |
Zhou Lab 16S, enigma_coral bricks |
SSO field genus occurrence (deliverable c, local) |
kbase.nmdc_arkin + nmdc_metadata |
covstats_taxonomy_rollup, sample_file_lookup, biosample_set |
Terrestrial/freshwater genus abundance + ENVO/GOLD env labels (deliverable c, global) |
planetmicrobe.planetmicrobe |
run_to_taxonomy, taxonomy, run/experiment/sample/project/campaign |
Marine genus abundance contrast (deliverable c, global) |
Generated Data
| File | Rows | Description |
|---|---|---|
data/resolved_compounds.tsv |
83 | Compound → InChIKey/SMILES + DB cross-refs |
data/compound_linkage.tsv / _deepened.tsv |
83 | Per-compound pathway/enzyme linkage + tier |
data/compound_organism_predictions.tsv |
948 | Pathway/enzyme → organism predictions |
data/compound_organism_dark.tsv |
75 | Organism-dark compounds + reason (pre-I1; lauric acid reclassified callable downstream, leaving 74 dark in the master table) |
data/fb_inchikey_matches.tsv |
1 | NB02c structural (InChIKey) FB carbon-source Tier-1 match: lauric acid |
data/enigma_utilizer_predictions.tsv |
569 | Deliverable (a): per-compound ENIGMA isolate utilizers |
data/phylo_utilizer_map.tsv |
494 | Deliverable (b): strain placements + certainty |
data/cooccurrence_matrix.tsv |
28 | H2 pairwise co-occurrence (φ, p, q) |
data/cooccurrence_effects.tsv |
28 | H2 effect sizes (review I4): Haldane OR + 95% CI, Jaccard, per pair |
data/compound_physicochem.tsv |
83 | NB09: PubChem physicochemical descriptors (MW, XLogP, TPSA, complexity, …) |
data/dark_matter_taxonomy.tsv |
74 | NB09: post-I1 dark compounds bucketed (orphan / no-reaction / biosynthesis-known / generic) |
data/environmental_atlas.tsv |
156 | Deliverable (c) local: SSO field genus occurrence |
data/env_atlas_global.tsv |
400 | Deliverable (c) global: genus × biome abundance (NMDC + PM) |
data/env_enrichment_soil_fresh.tsv |
83 | Soil-vs-freshwater abundance contrast (exploratory) |
data/env_outlier_samples.tsv |
249 | Label-free top genus×sample abundance spikes |
data/census_master_summary.tsv |
83 | One row per compound: the master census table |
References
See references.md for the full list. Core data sources: PubChem (Kim et al., Nucleic Acids Res. 2023); KBase (Arkin et al., Nat. Biotechnol. 2018); Fitness Browser / RB-TnSeq (Price et al., Nature 2018); GTDB (Parks et al., Nucleic Acids Res. 2022); ModelSEED (Henry et al., Nat. Biotechnol. 2010); NMDC (Eloe-Fadrosh et al., Nat. Microbiol. 2022); Planet Microbe (Ponsero et al., GigaScience 2021); aromatic catabolism (Harwood & Parales, Annu. Rev. Microbiol. 1996).
Discoveries
- The ENIGMA Carbon Census is ~89% organism-dark (74/83 compounds with no isolate utilizer call) — the actionable product of a knowledge census can be the map of ignorance, and that map is biased exactly by chemical class (alkaloids/terpenoids dark, aromatics callable), not by sampling source (groundwater 90% vs necromass 88% dark).
- Callable catabolic capacity among these compounds is phylogenetically concentrated in Burkholderiales and is a specialist trait: 675 single-capacity genomes vs only 18 generalists (≥3 capacities). Cross-module co-occurrence is near-zero in share terms (Jaccard ≈ 0; only 25/3109 genomes carry both an aromatic and a non-aromatic capacity), even though a Haldane odds ratio surfaces a modest phenylethylamine×aromatic enrichment (OR ≈ 2.8–3.4) that is itself aromatic-derived — so versatility is a clade trait, not a portable module set.
- Directional only (n=9 callable, uncorrected p): "callable" tracks structural simplicity — callable compounds have median Complexity 133 vs 207 for dark (Mann–Whitney p=0.034, uncorrected) — and this is at least partly an annotation-coverage ceiling, since simple pollutant-adjacent aromatics are the molecules curated catabolism resources cover.
- The dark set is not uniformly orphan: 6 dark compounds (Tyramine, guanidineacetic acid, cinnamic acid, caffeic acid, palmitic acid, farnesol) are biosynthesis-known/catabolism-unknown — MIBiG-consult triage targets distinct from the 29 fully-orphan (no-KEGG) compounds.
- A periphyton (freshwater-biofilm) ENVO/GOLD class, separated out from bulk freshwater, surfaces a Comamonadaceae/Burkholderiales reservoir at ~97% prevalence that bulk-water labels hide — relevant for siting SSO-relevant enrichments.
Performance Notes
- Both NMDC covstats and Planet Microbe
taxonomy.nameare species-level; any genus-level abundance claim requires species→genus aggregation first. Filtering on bare genus names silently matches only near-zero genus-rank reference rows (the bug that first showed 0/68 marine genera). Any project doing genus-level abundance overcovstats_taxonomy_rollupor Planet Microberun_to_taxonomyneeds this rollup. - The NMDC abundance denominator is the set of covstats files that actually carry taxonomy (3825), not the larger
sample_file_lookuprow count (~6700) — using the lookup count deflates relative abundances by ~1.75×. - Sample-level environment labels come from
nmdc_metadata.biosample_set(joined to covstatssample_idviakbase.nmdc_arkin.sample_file_lookup), which gives 99% coverage across two ontologies — far better thanstudy_tableGOLD alone (~13%).
Data Collections
Planetmicrobe Planetmicrobe
planetmicrobe_planetmicrobe
PlanetMicrobe
NMDC BioSamples
nmdc_ncbi_biosamples
NMDC / NCBI
Pangenome Collection
kbase_ke_pangenome
KBase, DOE
Fitness Browser
kescience_fitnessbrowser
Price Lab, LBNL
ENIGMA CORAL
enigma_coral
ENIGMA SFA, LBNL
NMDC Multi-omics
nmdc_arkin
NMDC
Review
Summary
This is the second automated review of this project, conducted after the author applied fixes in response to REVIEW_1 (2026-06-09). All six suggestions from REVIEW_1 have been implemented cleanly: the H4 verdict is now explicitly stated in Finding 5 of the REPORT; R02107 (xanthine→urate) has been removed from the carbon allowlist in build_nb03.py with an explanatory comment; Discovery 6 (species→genus rollup bug) has been relocated from Discoveries to Performance Notes; the README Reproduction section now carries Spark-vs-local annotations for each notebook; Discovery 3 leads with a bold "Directional only (n=9 callable, uncorrected p):" qualifier rather than burying it in subordinate clauses; and Finding 8 states the clade-conservation denominator caveat before any specific carrier fractions. The project remains a methodologically mature, unusually honest knowledge census: 14 notebooks with saved outputs, 21 figures, requirements pinned, and a REPORT that treats the 89% organism-dark gap as the primary deliverable. Two minor residual items do not block submission: (1) the intermediate data files (e.g., compound_organism_dark.tsv) were not regenerated after the R02107 fix, so they still contain xanthine as callable — this is documented explicitly in the REPORT Limitations section with a re-run caveat, and the master summary (census_master_summary.tsv) carries the correct callable count; (2) beril.yaml still shows status: analysis rather than review. Neither is a scientific integrity concern.
Methodology
Research question and hypotheses: Unchanged from REVIEW_1 assessment — clearly stated, testable, with explicit null hypotheses (H1–H4 with stated H0 for each).
Approach: The compound-first → organism → environment pipeline is well-executed and documented. The tiered evidence scheme (T1 measured → T6 taxonomic prior) is consistently applied throughout.
Data sources: All collections correctly identified and tabulated in the REPORT Data section (collection names, table names, purposes). The Phase-1 stop-gate (linkage coverage check before expanding to organisms) was faithfully executed. DB naming conventions (dot-notation for SPIRE, Planet Microbe, kbase.nmdc_arkin) were correctly applied.
Reproducibility: Significantly improved since REVIEW_1. The README ## Reproduction section now includes:
- Execution order (00 → 01 → 02 → 02b → 02c → 03 → 04 → 05 → 05b → 06 → 07 → 07b → 08 → 09)
- Clear Spark-vs-local annotations (🌩 Spark required: NB03, NB04, NB05, NB06, NB07, NB07b, NB08; 💻 local/API only: NB00, NB01, NB02, NB02b, NB02c, NB05b, NB09)
- Prerequisites and output locations
All 14 notebooks carry saved outputs (code-cell outputs verified for NB00, NB02c, NB05b, NB08, NB09). Requirements are pinned in requirements.txt (pandas 3.0.2, scipy 1.17.1, pyspark 4.0.1, etc.).
Code Quality
NB03 allowlist fix (REVIEW_1 Suggestion 2): Confirmed. build_nb03.py now contains CATABOLIC_ALLOWLIST = {'R02612', 'R07202'} with a prominent comment: "DELIBERATELY EXCLUDED (review I, NB03 fix): R02107 xanthine → urate (xanthine oxidase) is the purine NITROGEN pathway, NOT carbon catabolism. It does not belong in a CARBON census allowlist; including it mis-scored xanthine as carbon-callable. Do not re-add it." The executed notebooks and data files were not regenerated after this fix — xanthine still appears as callable in the intermediate NB03/NB04/NB05 outputs — but this is explicitly documented in the REPORT Limitations section and in the callable-compound table footnote (†). The master summary correctly presents the effective callable count as 8 (enigma_isolate_call) + 1 (measured_fitness).
Notebook organization: Consistent setup → query → analysis → visualization → output structure throughout. Markdown intent cells at each stage. The build_nb*.py → .ipynb pipeline convention is applied consistently across all 14 notebooks.
Statistical methods: The Haldane-corrected OR + Jaccard addition in NB05b is well-implemented — computes n00 = 3109 − n11 − n10 − n01 from saved counts without Spark, adds 0.5 per cell (standard Haldane correction), and produces interpretable cross-block effect sizes that φ alone hid. The soil-vs-freshwater contrast (NB07b) is correctly labeled exploratory throughout, with the pseudoreplication caveat (all 83 genera reach q<0.05 under the naive per-sample rank test) disclosed in Limitations.
Pitfall adherence (against docs/pitfalls.md):
- Short strain name collision ([genotype_to_phenotype_enigma]): avoided by mapping directly on enigma_genome_depot_enigma; a genus cross-check is implemented in the plan-level notes.
- Commit notebooks alongside artifacts: all 14 numbered notebooks are present as .ipynb with saved outputs — no orphaned-artifact gap.
- Fitness Browser KO mapping as two-hop join: NB02c uses PubChem-resolved InChIKeys for FB matching, correctly bypassing the KO join entirely.
- Genus-level taxonomy aggregation: species→genus rollup correctly applied in NB07b; the bare genus-name filtering bug was caught and documented in Performance Notes.
- NMDC denominator: correctly uses 3825 taxonomy-bearing covstats files, not the inflated ~6700 lookup row count.
One cosmetic note: NB09 Part 1 boxplot cells use the deprecated matplotlib labels parameter (renamed to tick_labels in Matplotlib 3.9; support for old name drops in 3.11). The deprecation warning appears six times in the saved NB09 outputs but does not affect the figures.
Findings Assessment
All six REVIEW_1 suggestions have been addressed:
-
✅ H4 verdict stated explicitly (REVIEW_1 Suggestion 1): Finding 5 now includes: "H4 verdict (tier-stratified, phylogenetically concentrated isolate predictions per compound): partially supported — strongly for the 8 ENIGMA-isolate-callable compounds, null for the other 75."
-
✅ NB03 xanthine allowlist fixed (REVIEW_1 Suggestion 2): Code fix confirmed in
build_nb03.py(R02107 excluded with explanatory comment). Intermediate data files not regenerated — documented transparently in REPORT Limitations and in the callable-compound table footnote. -
✅ Discovery 6 relocated to Performance Notes (REVIEW_1 Suggestion 3): REPORT Discoveries section now has exactly 5 entries. The species→genus aggregation issue is Performance Note 1. Categorization is now accurate — methodology pitfalls in Performance Notes, biological findings in Discoveries.
-
✅ Spark vs local annotations added to README (REVIEW_1 Suggestion 4): README Reproduction section now has per-notebook Spark/local markers, directly addressing the barrier for off-cluster collaborators.
-
✅ Discovery 3 qualifier foregrounded (REVIEW_1 Suggestion 5): Discovery 3 now leads with bold "Directional only (n=9 callable, uncorrected p):" text rather than a subordinate clause. The annotation-coverage confound interpretation is also foregrounded.
-
✅ Clade-conservation denominator caveat promoted (REVIEW_1 Suggestion 6): Finding 8 now opens with the denominator caveat ("These conservation fractions are denominated over depot genomes that already carry some catabolic call — not a census of all genomes of each genus — so they describe within-called-set specialization, not absolute prevalence:") before any specific carrier fractions.
Adversarial review items (carried through REVIEW_1) are closed:
- β-ketoadipate claim narrowed to "six of the eight callable compounds" ✅
- Phenylethylamine's paa/phenylacetyl-CoA route correctly distinguished ✅
- "Validates the linkage chain" corrected to "validates the taxonomic/abundance pipeline" ✅
- Burkholderiales periphyton enrichment attributed to project's own NB07b data, not external citation ✅
One minor data inconsistency noted: data/compound_organism_dark.tsv contains 75 rows (pre-I1 state, including lauric acid), while data/dark_matter_taxonomy.tsv has 74 rows (post-I1, lauric acid correctly removed). The REPORT's Generated Data table documents this with a parenthetical "(pre-I1; lauric acid reclassified callable downstream, leaving 74 dark in the master table)." The master summary is correct and self-consistent. Downstream users reading only compound_organism_dark.tsv could be confused if they miss the footnote, but this is documented and not a scientific integrity concern.
Limitations: Comprehensive and internally consistent. The soil-vs-freshwater p-value inflation, abundance ≠ activity, catabolic-direction filter dependence, xanthine category error, terephthalic certainty artifact, resource-darkness ≠ scientific darkness, and marine arm scope are all disclosed. The limitations section is one of the strongest aspects of the project.
Suggestions
-
(Priority: low) Regenerate NB03→NB04→NB08 with the corrected R02107 exclusion before the final archived commit. The code fix is confirmed and documented, but having xanthine appear as callable in the executed intermediate notebooks (NB03 outputs,
enigma_utilizer_predictions.tsvcount of 569,cooccurrence_matrix.tsvincluding xanthine pairs) while the REPORT says it is not a true carbon-callable creates a gap between "live code story" and "archived outputs story." The master summary is already correct. A re-run of the Spark notebooks would produce a fully self-consistent archive (8 enigma_isolate_call compounds, 567 utilizer rows, 26 co-occurrence pairs). This is a data-hygiene issue, not a scientific integrity one. -
(Priority: low) Update
beril.yamlstatus fromanalysistoreview. The README states "Analysis — report drafted (review fixes applied); REVIEW_1.md is stale, awaiting fresh/berdl-reviewand/submit." The current status field does not reflect the project stage. -
(Priority: low) Fix the NB09
labels→tick_labelsdeprecation warning. Inbuild_nb09.pyPart 1, replacelabels=[...]withtick_labels=[...]in the sixax.boxplot()calls. The deprecation warning is visible in the saved NB09 outputs and will become a hard error in Matplotlib 3.11. Cosmetic and forward-compatibility hygiene only; figures are correct. -
(Priority: informational) Propagate Performance Note 1 (species→genus rollup) to
docs/pitfalls.mdvia/pitfall-capturebefore submitting. Performance Note 1 is exactly the kind of gotcha that belongs in the repository-level pitfalls archive. Any future project querying NMDC or Planet Microbe at genus level needs this warning. The note is already well-worded; extracting it to docs/pitfalls.md would make it discoverable by future agents without requiring them to read this project's REPORT.
This review was generated by an AI system. It should be treated as advisory input, not a definitive assessment.
Visualizations
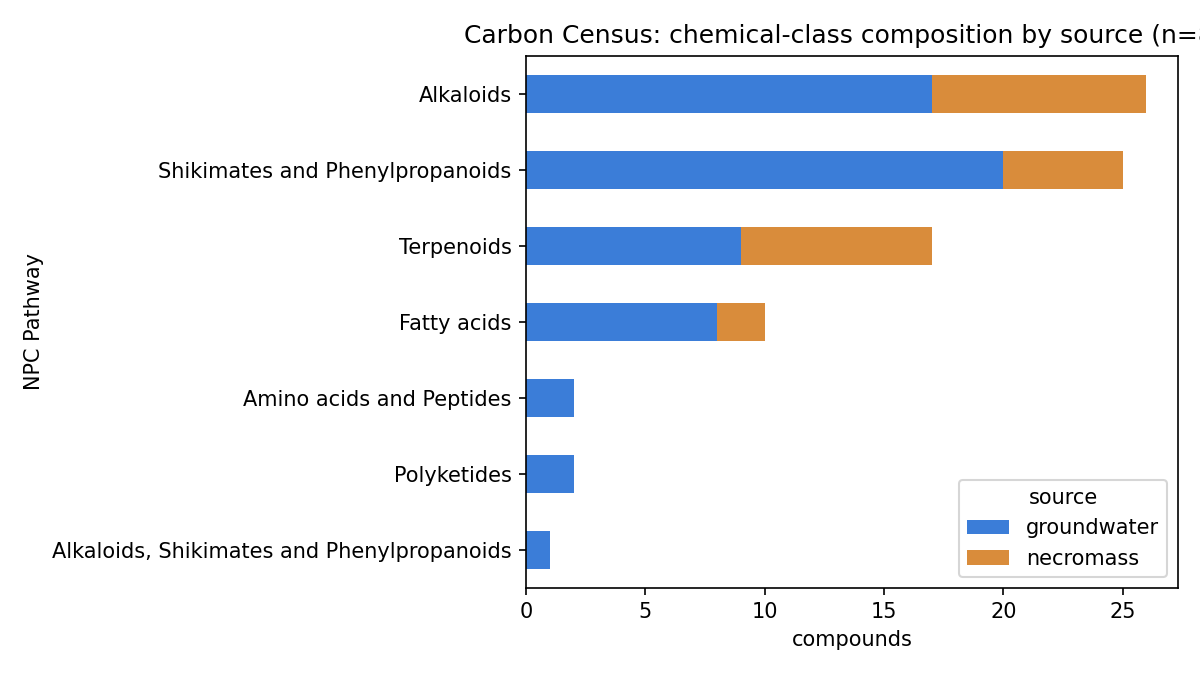
00 Class Composition
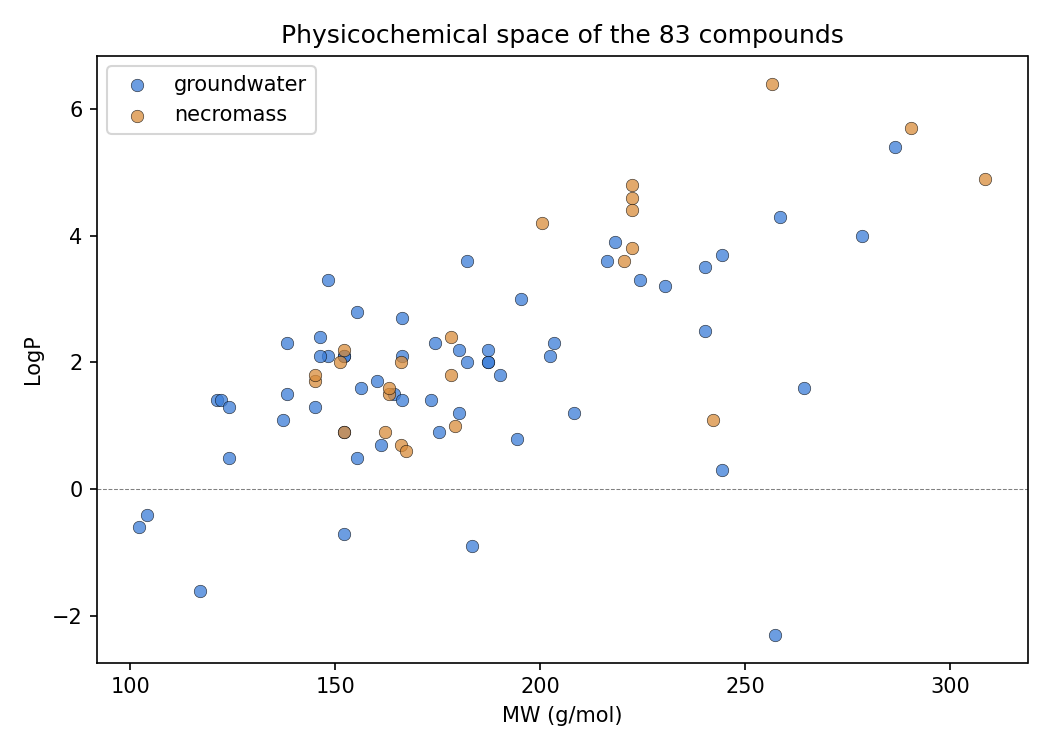
00 Mw Logp
02 Linkage Coverage
02B Linkage Deepened
03 Organism Calls
04 Utilizer Genera
05 Cooccurrence
05 Genus Versatility
05 Versatility
05B Odds Ratio Forest
06 Certainty Composition
06 Phylo Order Map
07 Field Occurrence
07B Env Atlas Heatmap
07B Soil Fresh Enrichment
08 Funnel
09A Bioavailability Space
09A Physicochem Callable Dark
09B Chassis
09C Clade Conservation
09D Dark Taxonomy
Notebooks
00_compound_profile.ipynb
00 Compound Profile
View notebook →
01_identity_resolution.ipynb
01 Identity Resolution
View notebook →
02_pathway_linkage.ipynb
02 Pathway Linkage
View notebook →
02b_linkage_deepening.ipynb
02B Linkage Deepening
View notebook →
02c_fb_inchikey_rematch.ipynb
02C Fb Inchikey Rematch
View notebook →
03_organism_mapping.ipynb
03 Organism Mapping
View notebook →
04_enigma_utilizers.ipynb
04 Enigma Utilizers
View notebook →
05_cooccurrence.ipynb
05 Cooccurrence
View notebook →
05b_cooccurrence_effects.ipynb
05B Cooccurrence Effects
View notebook →
06_phylo_maps.ipynb
06 Phylo Maps
View notebook →
07_environmental_atlas.ipynb
07 Environmental Atlas
View notebook →
07b_environmental_atlas_global.ipynb
07B Environmental Atlas Global
View notebook →
08_synthesis.ipynb
08 Synthesis
View notebook →
09_deepening.ipynb
09 Deepening
View notebook →
Data Files
| Filename | Size |
|---|---|
census_master_summary.tsv |
10.6 KB |
compound_linkage.tsv |
18.8 KB |
compound_linkage_deepened.tsv |
17.9 KB |
compound_organism_dark.tsv |
6.3 KB |
compound_organism_predictions.tsv |
175.7 KB |
compounds_selected.tsv |
11.2 KB |
cooccurrence_matrix.tsv |
2.7 KB |
deepen_cache.json |
434.1 KB |
enigma_utilizer_predictions.tsv |
161.1 KB |
env_atlas_global.tsv |
59.9 KB |
env_enrichment_soil_fresh.tsv |
15.9 KB |
env_outlier_samples.tsv |
37.1 KB |
environmental_atlas.tsv |
20.7 KB |
fb_pubchem_cache.json |
7.3 KB |
phylo_utilizer_map.tsv |
107.8 KB |
pubchem_cache.json |
292.2 KB |
pubchem_properties_cache.json |
15.7 KB |
resolved_compounds.tsv |
14.8 KB |